
Did you know that more than 70 zettabytes of data were created, captured, and consumed last year alone? That is like a trillion gigabytes!
The great news is that public data can be scraped and used for a wide range of purposes including:
Getting data from eCommerce product catalogues
Finding B2B prospects for different industries
Collecting customer reviews
Research and more…
This massive amount of data is open to the public and may be simply scraped for information about businesses, competitors, possible opportunities, and trends.
In this tutorial, we will walk you through how to scrape data from a website easily and with no coding skills. We took a popular web directory called Clutch to find top-ranking marketing agencies you could contact to sell your services.
To do this we will be using our Hexomatic scraping recipes to enable you to scrape data from a website in minutes via a point-and-click browser.
Let’s get started.
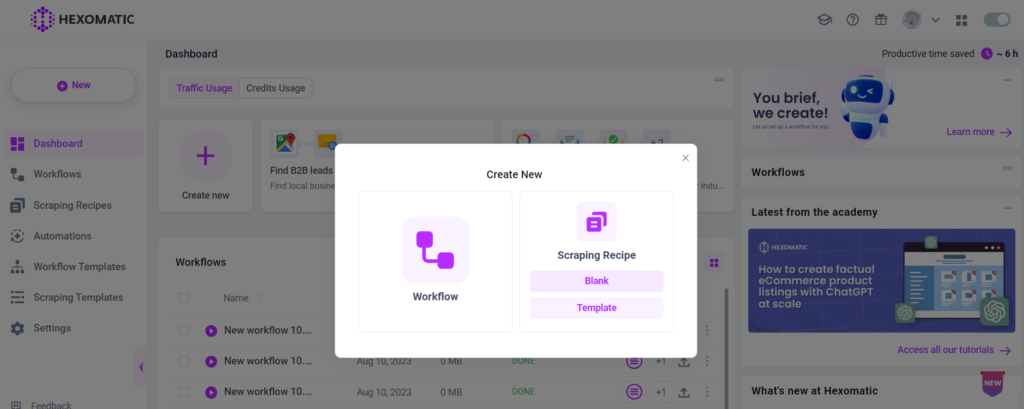
Step 1: Create a scraping recipe
To get started, create a blank scraping recipe in Hexomatic.com
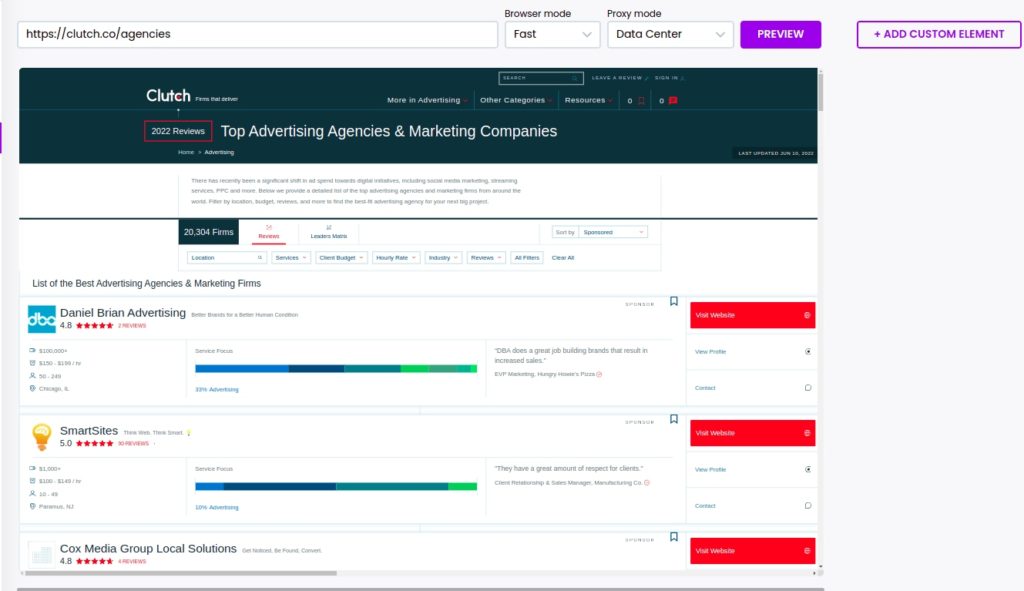
Step 2: Add the website URL
Go to the website page from which you want to scrape data from.
In this case, we are going to use a website directory category that is displaying a list of top-ranking advertising agencies.
Copy-paste the URL in the Hexomatic scraping recipe builder URL bar.
Then, click Preview.
Step 3: Choose the elements to scrape from a webpage
In this section, we will show you how to easily scrape different elements from the webpage.
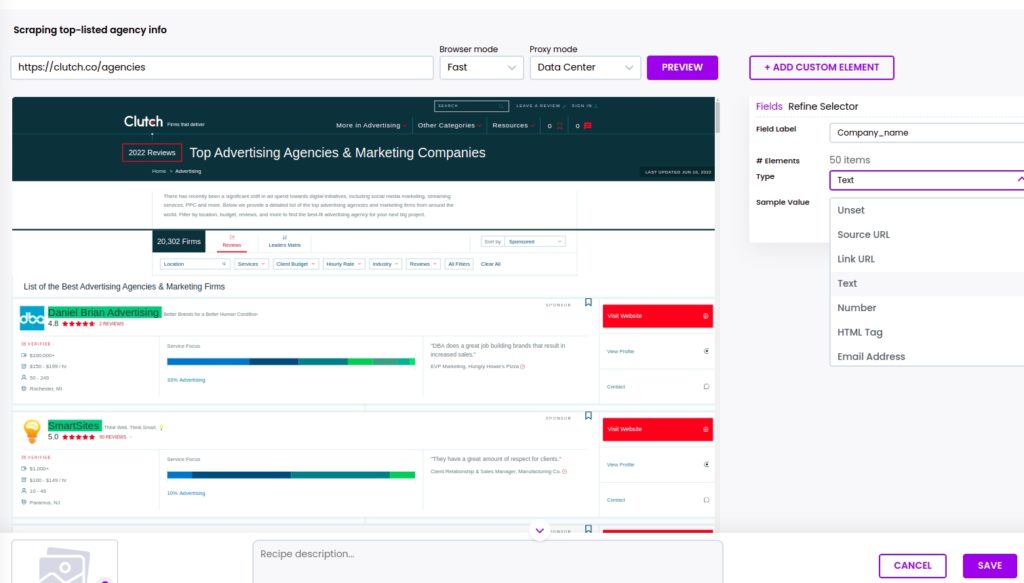
Step 1: Scrape titles
Choose whether you want to select that specific element only or select all the matching elements found on the page. It can be text, number, URL, HTML tag, and more.
In this case, use the “select all” option to get all the titles detected on the page.
You can set the element type as text if you want to save the text of the title or select the link URL for scraping the title URLs.
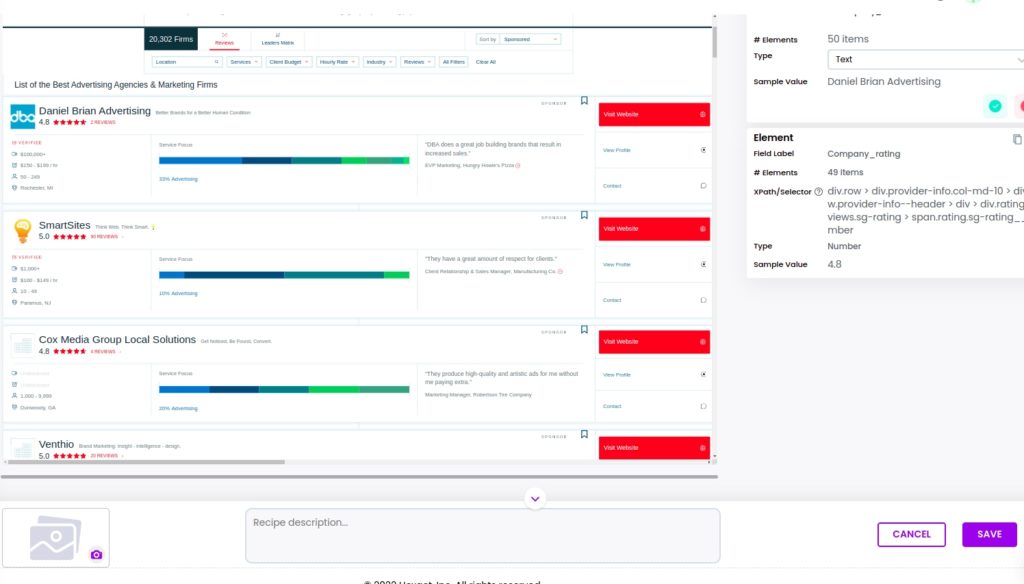
Step 2: Scrape company ratings
Next, you can select and scrape the rating of each company. To do that, select the rating of the first company and click “Select all” from the actions bar to scrape all the company ratings captured on the page.
Step 3: Scrape other company data
You can also scrape the number of employees for each company, its minimum project size, hourly rate, number of employees, and location. Choose the element type and click Save.
Using this logic, you can scrape any data from the webpage.
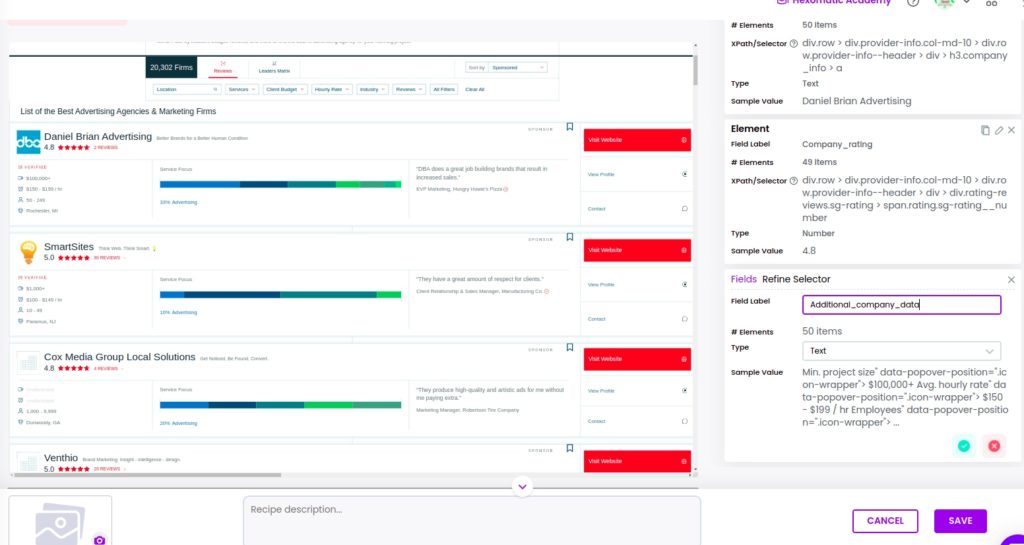
Step 4 Save the scraping recipe
Click save to save the scraping recipe.
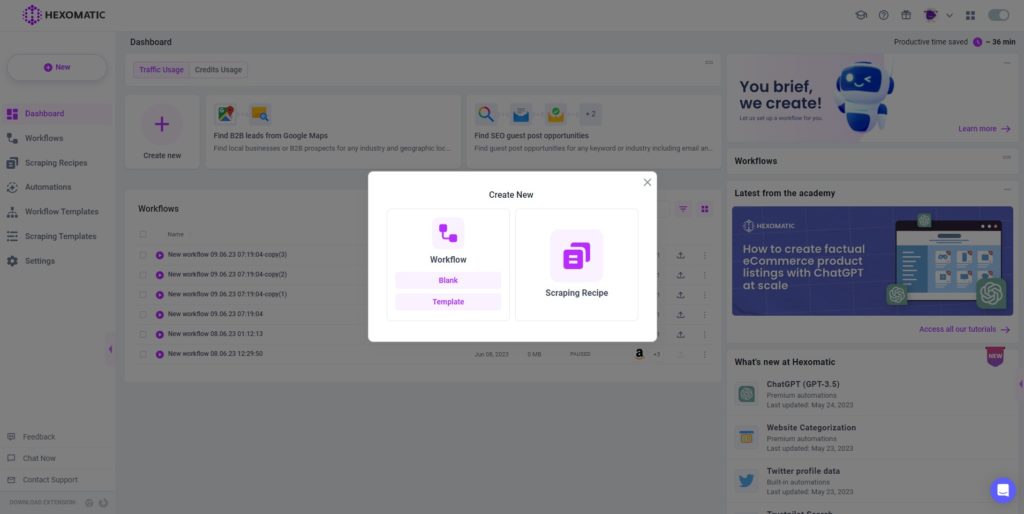
Step 4: Create a new workflow
From your dashboard, create a new workflow by choosing the “blank” option. Then, select Data automation as a starting point.
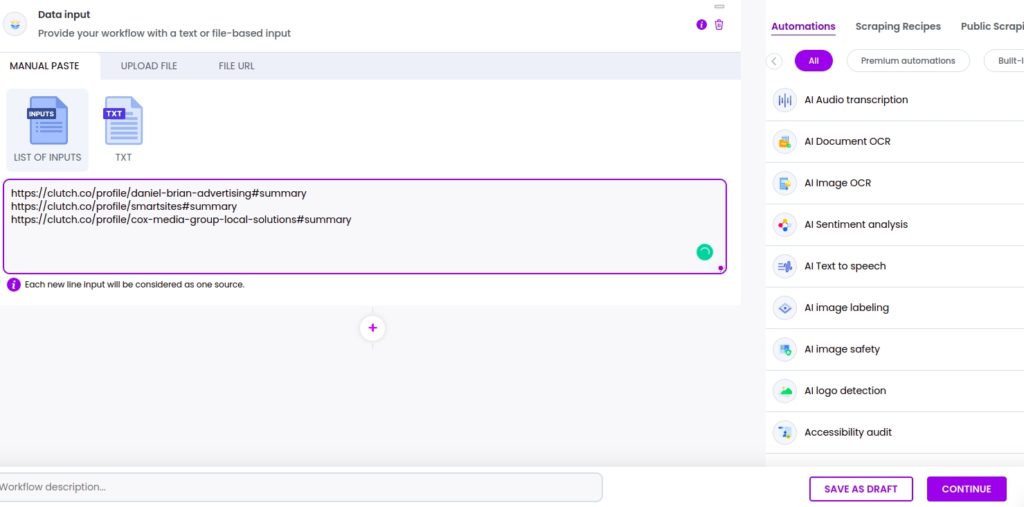
Step 5: Add URLs of category pages
Now, you can add the URLs of other category pages (SEO firms, mobile applications developers, etc.) and add these as a source to scrape from these pages automatically.
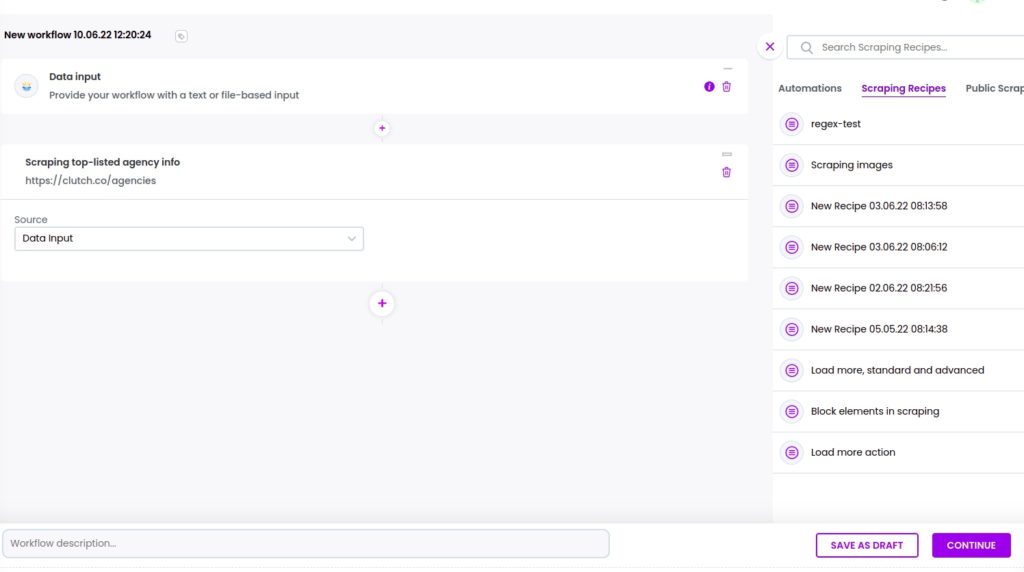
Step 6: Add your scraping recipe to the workflow
Add your previous scraping recipe to the workflow, selecting data input as the source. Then, click Continue.
Step 7: Run or schedule your workflow
After running the workflow, you will get the data from all the inserted URLs.
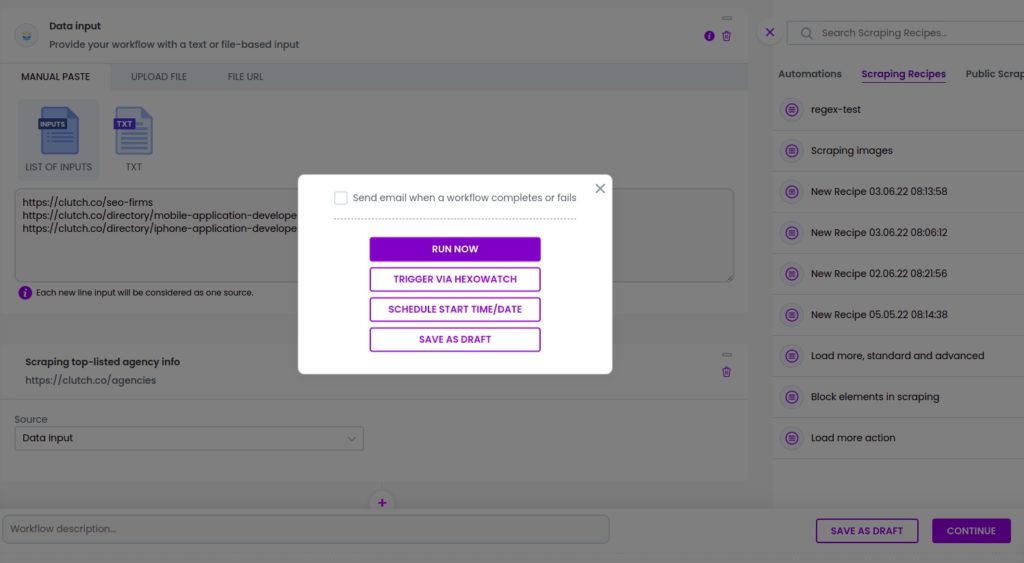
Step 8: View and save the results
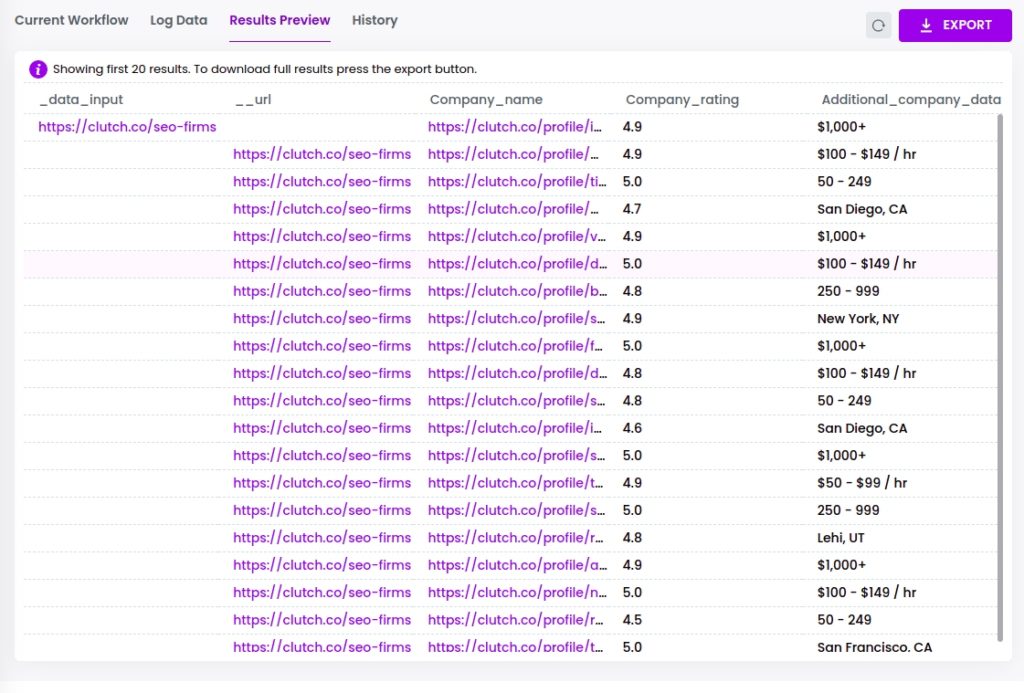
Now, you can view the results of the workflow.
You can then export it to CSV or Google sheets.
Automate & scale time-consuming tasks like never before
Marketing Specialist | Content Writer
Experienced in SaaS content writing, helps customers to automate time-consuming tasks and solve complex scraping cases with step-by-step tutorials and in depth-articles.
Follow me on Linkedin for more SaaS content