
Say goodbye to tedious copy-pasting. Our scraping recipe builder enables you to turn any page into a spreadsheet, extracting fields from websites using a simple point and click interface. No coding required.
In this tutorial, we will cover custom actions, an advanced feature of our scraping recipe builder which enables you to perform a wide range of actions including pagination, clicking, typing, and more just like the web browser you use on your computer.
- How to access custom actions in the scraping recipe builder
- How to scrape using Standard and Advanced pagination
- How to use Advanced pagination
- How to use Click and Type action
- How to use the advanced click and type action
- How to use the load more action in a scraping recipe
- How to use the advanced load more custom action
- How to use the “Go to URL” action
- How to use the scroll action
- How to use the Delay action
- How to use the refresh action
- How to use the block elements action
- How to use specific local storage
- How to set cookies manually using a custom action
How to access custom actions in the scraping recipe builder

Before getting to explore each of the custom actions in detail, let’s see how to access custom actions in a scraping recipe builder.
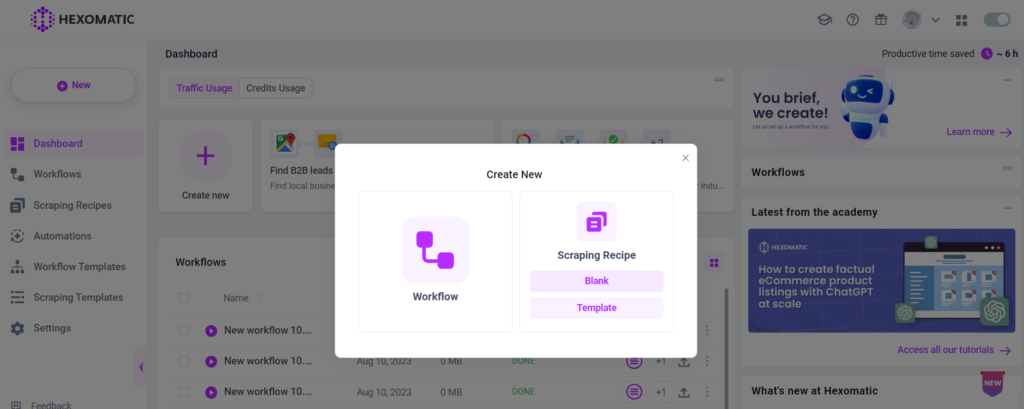
Step 1: Create new scraping recipe
To get started, create a new scraping recipe from your dashboard.
Step 2: Load web page to scrape
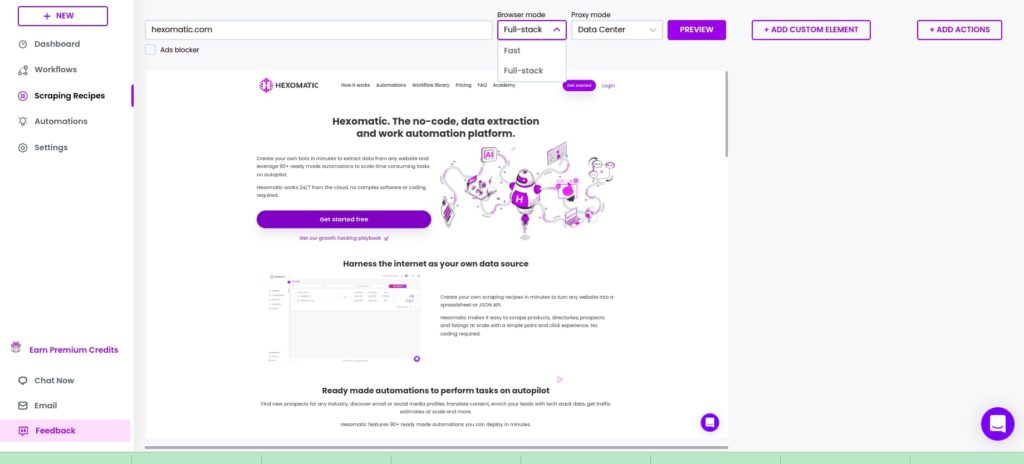
Next, load the web page to scrape by adding its URL and clicking Preview.
Before the Preview, you should choose the browser mode (Fast/ Full-stack). Note that not all actions are supported in the Fast mode. For the advanced actions, you should choose the Full-stack mode.
Step 3: Click “Custom actions”
Next, click Add actions to see the “Custom actions” pop-up.
You can now choose your custom action.
How to scrape using Standard and Advanced pagination

In this section, we will show you how to scrape data from all the pages of a given website in just a few clicks using standard and advanced pagination.
Let’s start with standard pagination which tries to automatically detect the pagination structure on a page.
How to use standard pagination
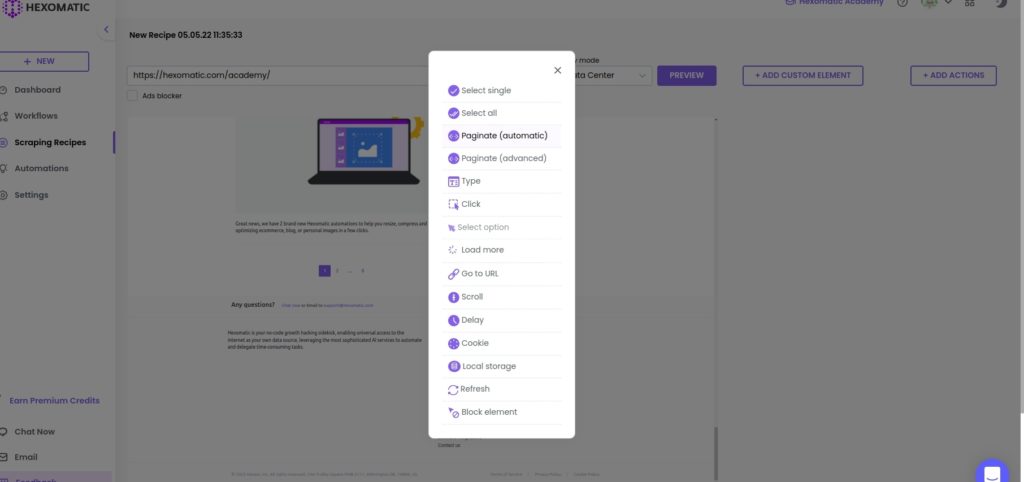
Step 1: Click the area around the pagination
To get started, click the area of pagination at the bottom of the webpage to detect all the links to the pages in the navigation. Then, click Paginate (Automatic) in the pop-up window.
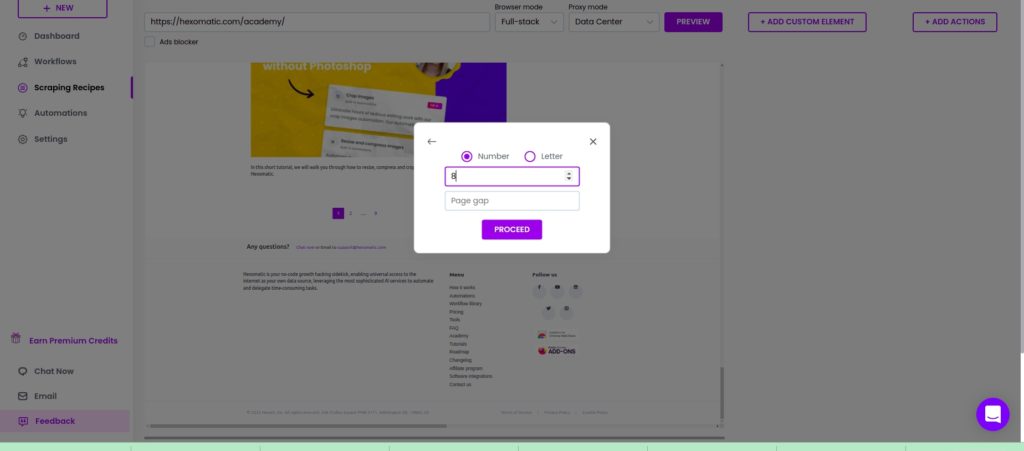
Step 2: Specify the pages to paginate
Next, specify the pages to paginate. Select Number if the pages are marked in numbers, and Letter once the pages are marked in letters.
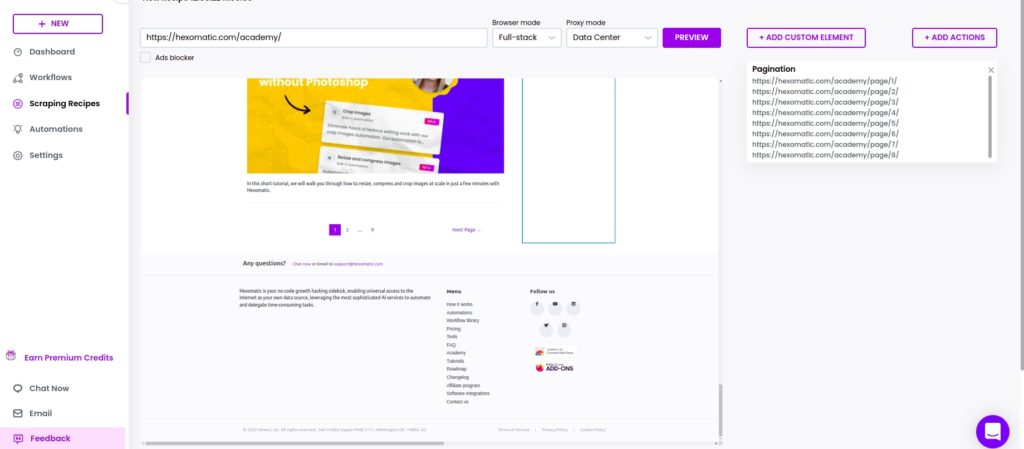
Step 3: Click Proceed
After proceeding, the URLs of the pages will appear on the right side of the window.
How to use Advanced pagination
If you are unable to click on the area of pagination at the bottom of the page, then you can use advanced pagination.
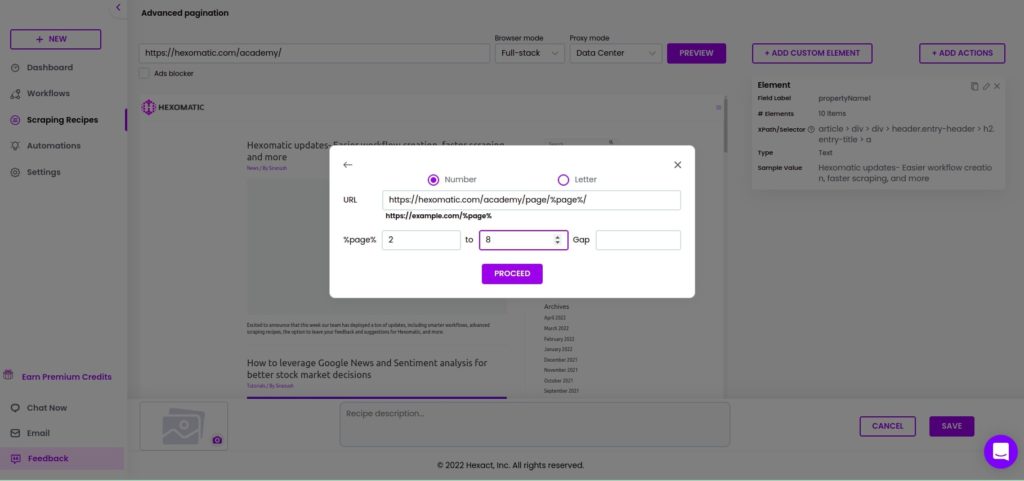
Step 1: Use advanced pagination
After choosing the advanced pagination option from the pop-up window, add the URL of the targeted website, in the form displayed in the window as an example. (https://example.com/%page%). Then, add the pages to be scraped and click Proceed.
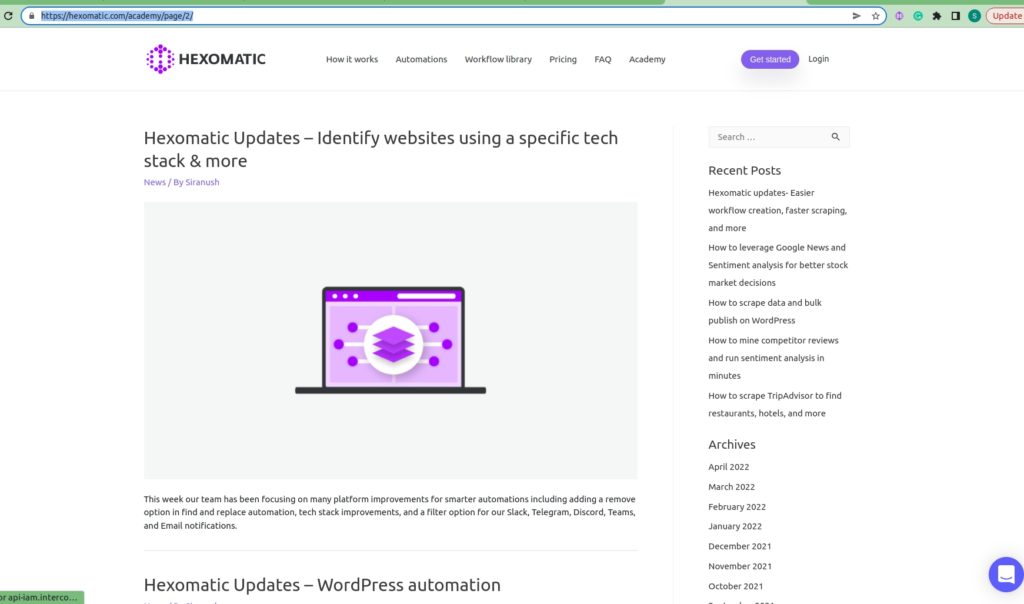
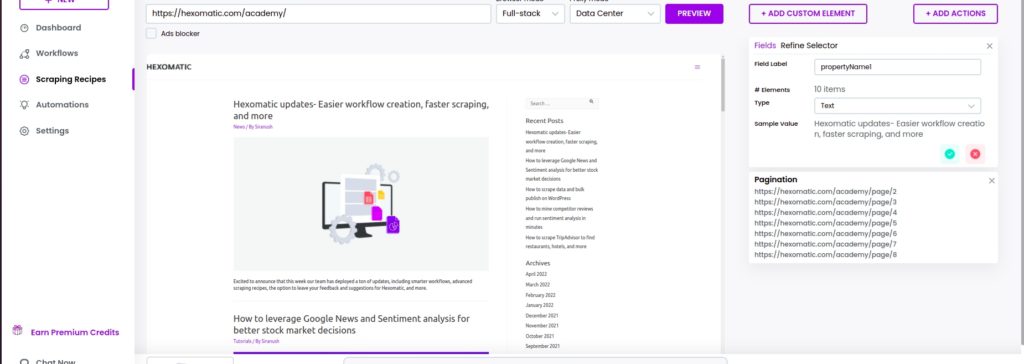
Step 2: Click proceed to see the results
After proceeding, the URLs of the paginated pages will be displayed on the right side of the window.
How to use Click and Type action
Our scraping recipe builder works just like your web browser, enabling you to click and type text or passwords into fields. This is ideal to login into password-protected pages or perform searches.
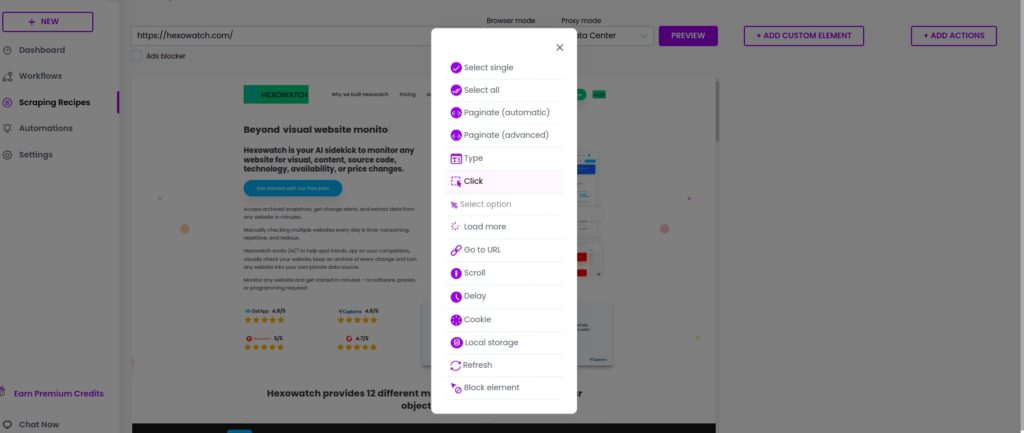
Step 1: Use the Click option
After loading your page click on the button or link to access our custom actions and use the click action.
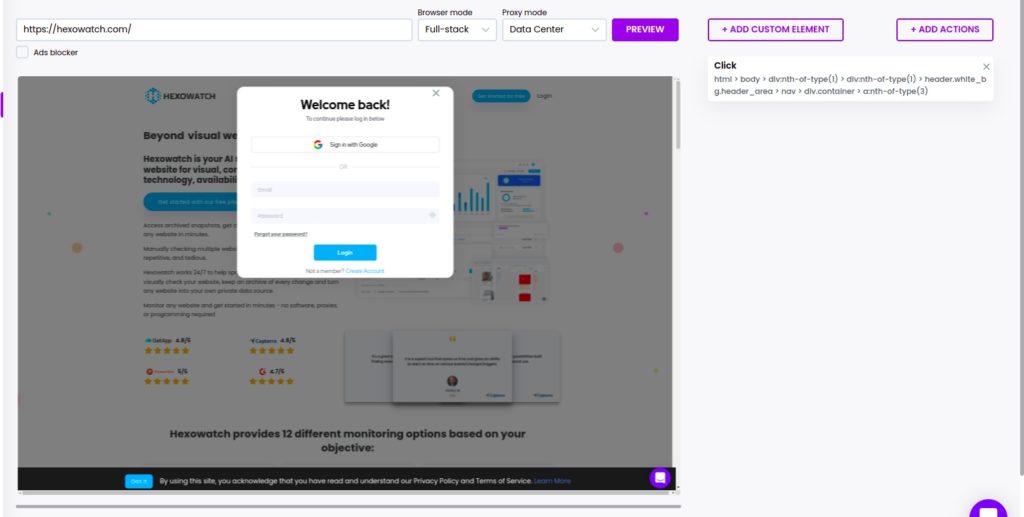
After performing the click action, Hexomatic will load the destination page.
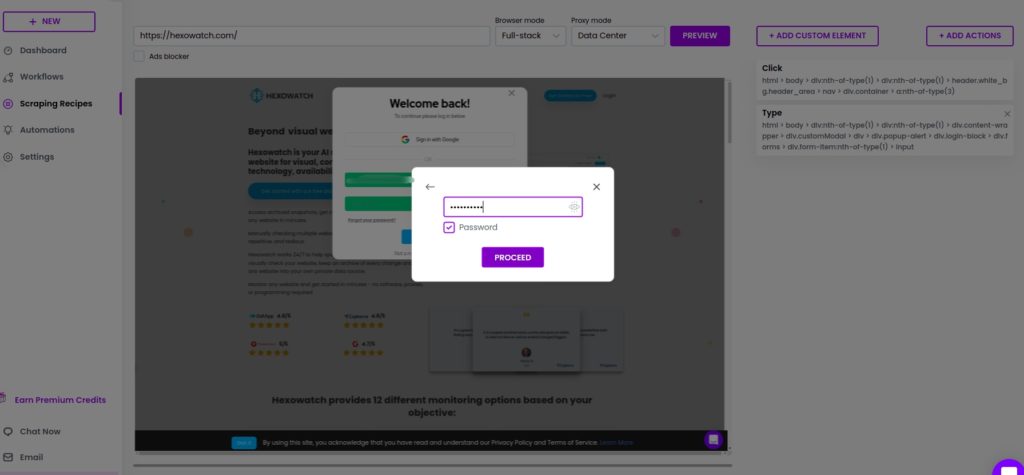
Step 2: Using the Type action for text and passwords
Click any form field to see the custom actions pop-up, then use the type action to enter text, or the password option to ofuscate the text in the appropriate fields.
Type username
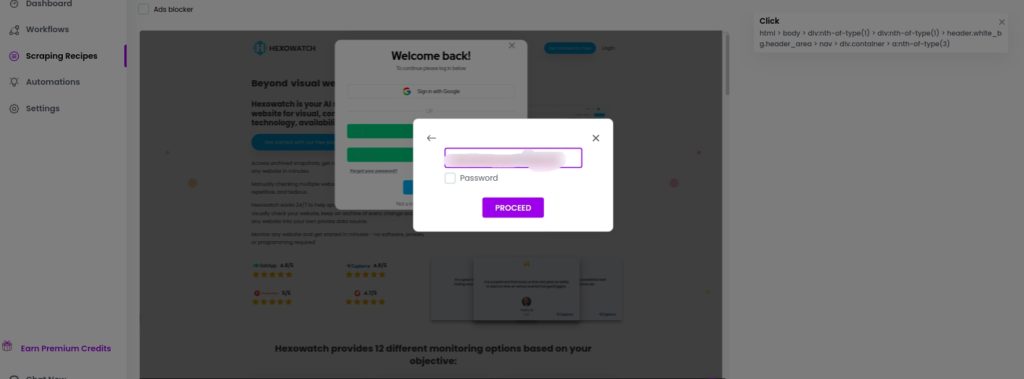
Type password
How to use the advanced click and type action
In cases when it is not possible to automatically select elements directly, you can use the advanced click and type custom actions to specify elements using Xpath or CSS selectors.
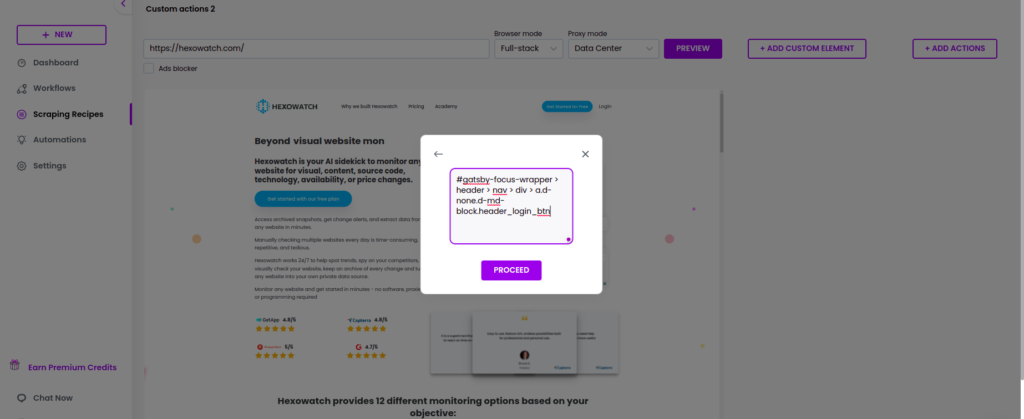
Step 1: Go to the website you want to scrape
If you are unable to perform the click action right in the scraping recipe builder, then access the page using your Chrome or other web browser and use developer tools to get the XPath/selector of the desired element. In the gif below, we are getting the selector of the Login button using Chrome.
Step 2: Paste the login button selector
Get back to the scraping recipe builder, select Click, and paste the copied Xpath/selector into the window. Then, click Proceed.
Step 3: Use copy and type custom actions to log into the account
After proceeding, a window will appear to fill in the username and password.
Add Actions, choosing Type. Then, add your username and paste the username selector copied from the targeted website.
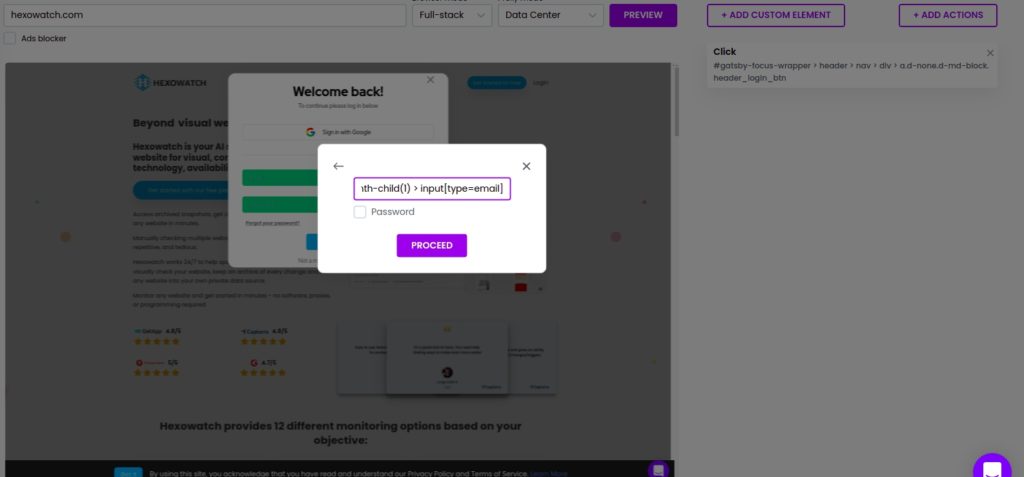
Then, repeat the actions for inserting the password.
Step 4: Use the Click action to log into the account
After pasting the Xpath/selector, use the Click action again to log into the account right from the scraping recipe builder.
To do that, copy the Xpath/selector of the login button and paste it into the window.
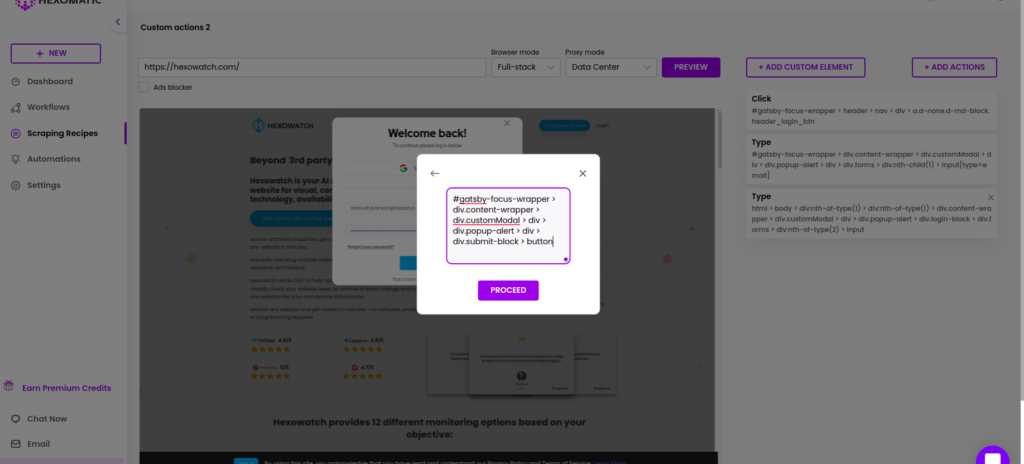
After proceeding, you will log into your account.
How to use the load more action in a scraping recipe

With Hexomatic, you can scrape data not only from the websites that enable pagination but from the ones that use the ‘load more’ option for loading the website content. With this option, you can scrape an impressive amount of data with just a few clicks.
In this section, we will demonstrate how to use the standard ‘load more’ action in the Hexomatic scraping recipe builder to scrape more data.
Before starting, be sure to set the browser mode to Full-stack.
Step 1: Click the “load more” action in the scraping recipe builder
After adding the URL of the website to scrape, get to the bottom of the page and click “Load more”.
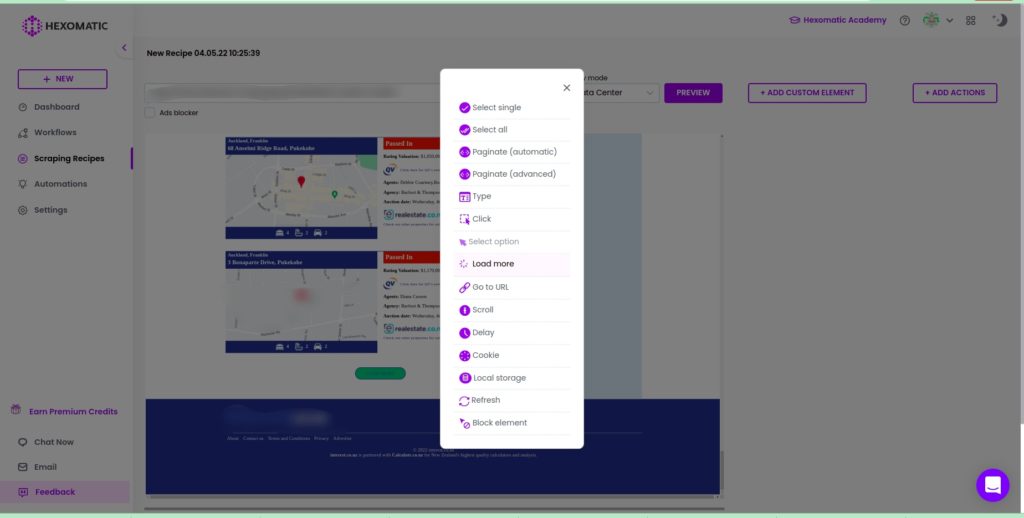
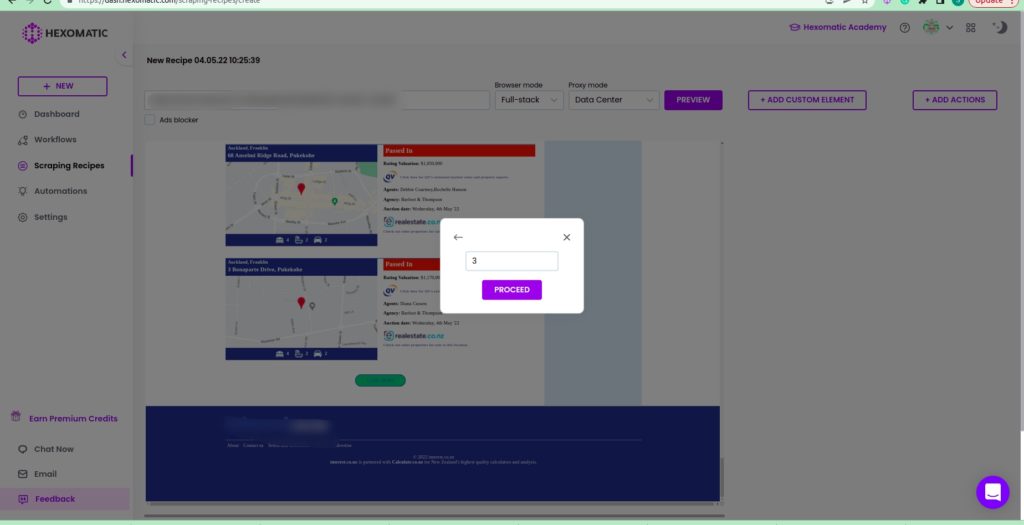
Step 2: Add the click count and proceed
Next, add the click count (the number of pages to be load) and proceed to load the page.
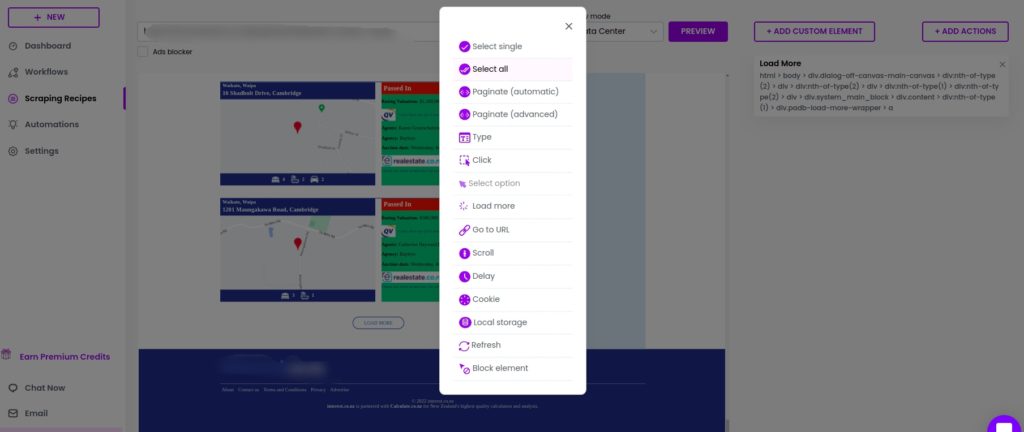
Step 3: Select the elements to scrape
Now, you can select the elements from the loaded pages as well. Click Select all to scrape all the elements of the same category, choose the type of the element and Save.
You can then use the scraping recipe in a workflow and export the data to Google Sheets or CSV file.
How to use the advanced load more custom action
In cases when you are unable to click “load more” right in the scraping recipe builder you can turn to the advanced
Many websites use the load more option instead of pagination to display website content. While scraping, you may come across this kind of website and not be able to click on the load more button right in the scraping recipe.
In this section, we will walk you through how to scrape content that is not displayed on the main page and can be visible only after using the load more option. In such scenarios, our Hexomatic load more custom element will come to the rescue.
Step 1: Create a new scraping recipe
To get started, create a new scraping recipe from your dashboard.
Step 2: Add the URL of the website to scrape
Next, add the URL of the website you want to scrape, select Full-scale as the browser mode and click Preview.
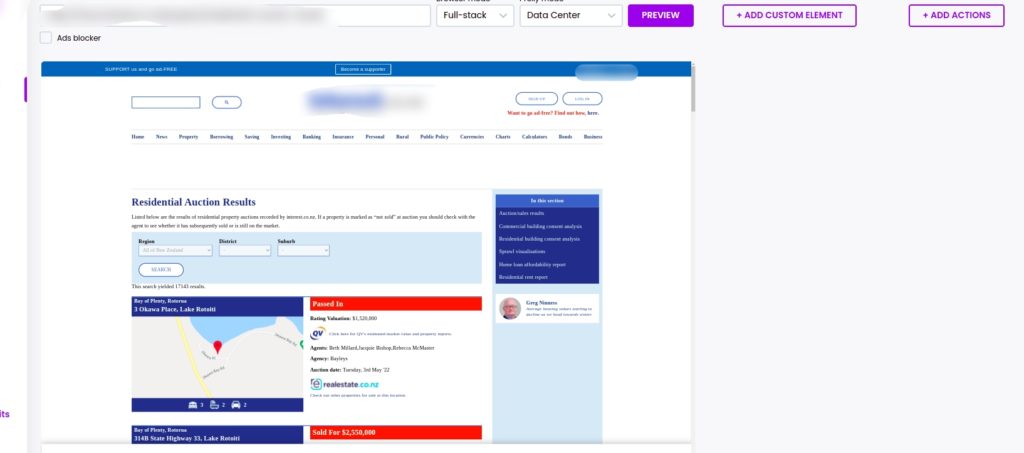
Step 3: Use the load more custom action
In case the load more option is not working on the scraping recipe, you can use its Xpath/ selector. To start, click Add actions from the right corner of the window, selecting Load more (custom selector).
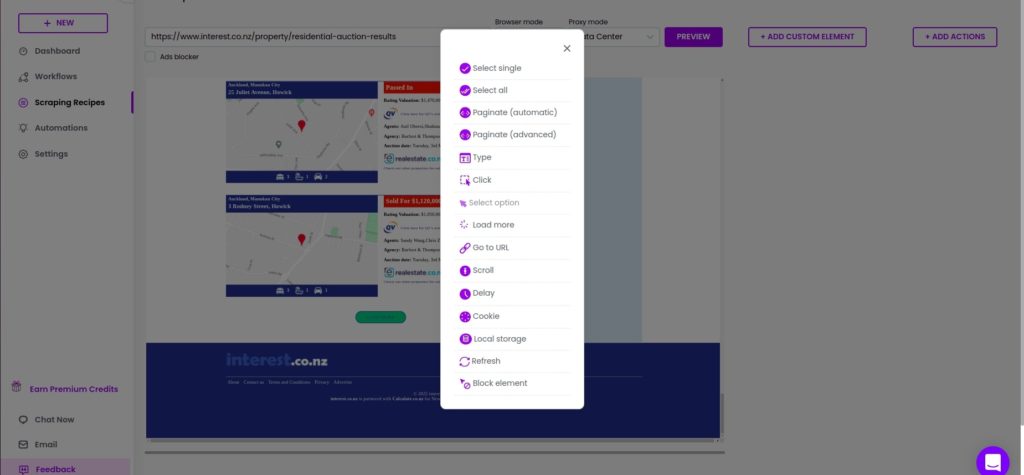
Step 4: Go to the website you want to scrape
Now, go to the website you want to scrape and inspect it. Select the load more element and copy its Xpath/selector.
Next, paste the copied Xpatch selector into the window, which appeared after selecting the load more (custom selector). Choose desired click count and Click proceed.
After proceeding, the page will load, and you can select all the elements you want to scrape.
Step 5: Use the scraping recipe in a workflow
You can use the scraping recipe in a workflow and save the results in Google Sheets or CSV.
How to use the “Go to URL” action

Once you have added the website you want to scrape, you may discover that you have to access another page on the current site. Hexomatic allows you to get to the desired URL right in the scraping recipe builder. In this section, we will show you how to perform that action in a few clicks.
Before starting, be sure to set the browser mode to Full-stack.
Step 1: Go to the webpage you want to switch to
Go to the webpage you want to scrape and copy its URL.
Step 2: Select the “Go to URL” action and paste the copied URL
Select the “Go to URL” action from the custom actions pop-up window and paste the copied URL.
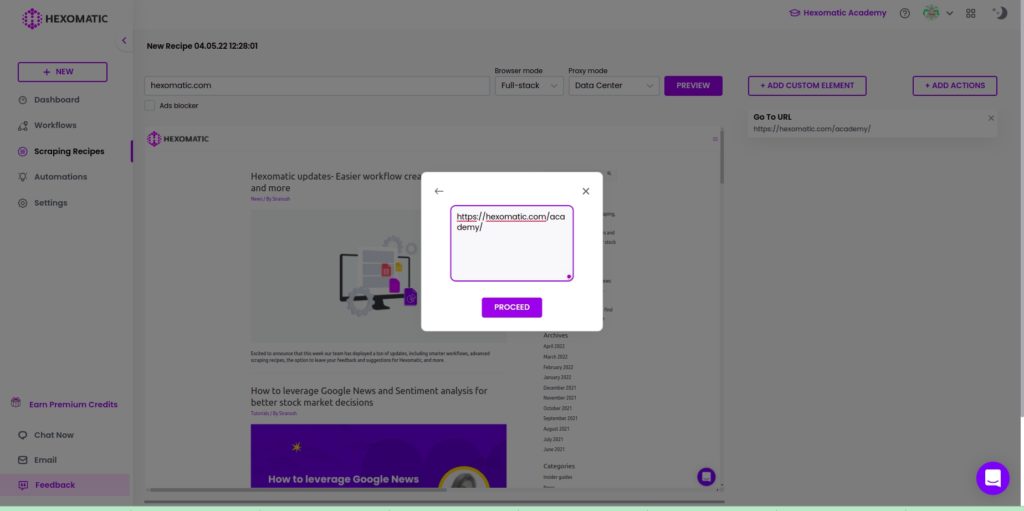
Step 3: Click Proceed to open the page
Click process to open the desired page. Now, you can select the items to scrape.
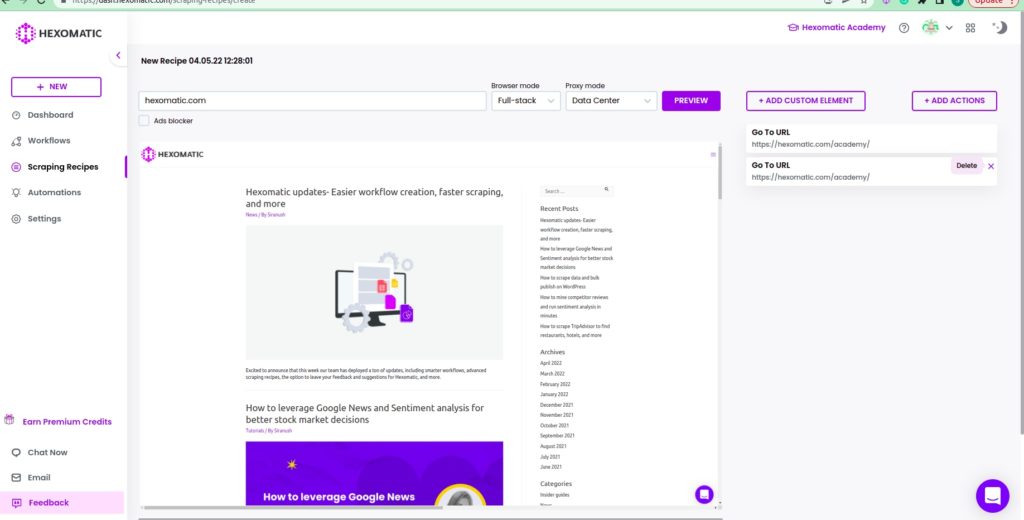
How to use the scroll action
With Hexomatic, you don’t have to worry about scraping websites that don’t have pagination but allow scrolling instead.
Before getting started, be sure to set the Full-stack mode for the browser.
Step 1: Use the scroll action
After loading the website, choose the scroll action from the custom actions pop-up window. Then, input the scroll size (In this case, we select 8000 px).
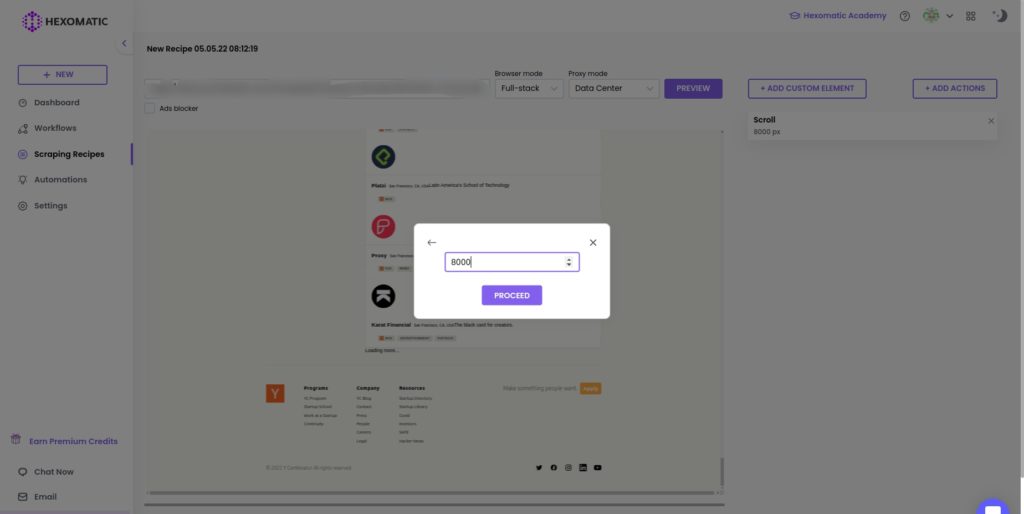
Step 2: Click proceed to load more results
After inputting the scroll size, click proceed to load more results.
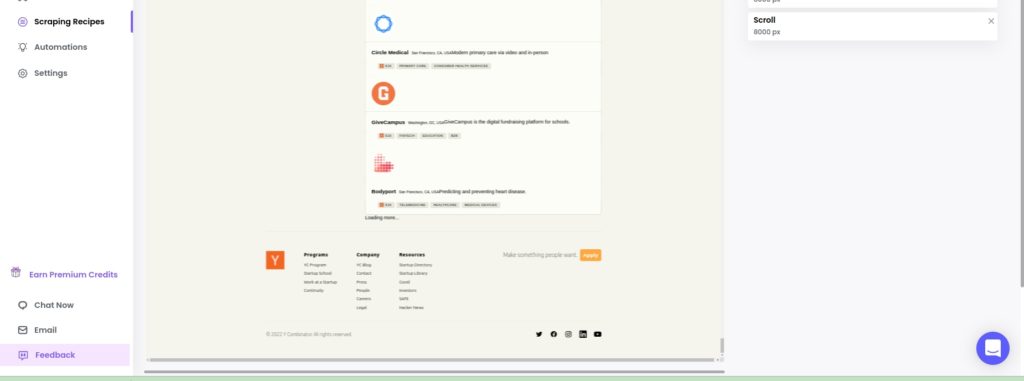
Now, you can select elements to scrape and save the results.
How to use the Delay action

Some websites take longer to load than others. To ensure a page has time to fully load all assets (includng images, CSS and scripts) you can set a custom delay before displaying the page preview in Hexomatic.
Before starting, note that this option is enabled only for the Full-stack browser mode.
Step 1: Use the delay action
After inserting the website URL and seeing that it doesn’t load properly, add the delay action and set the delay interval in seconds.
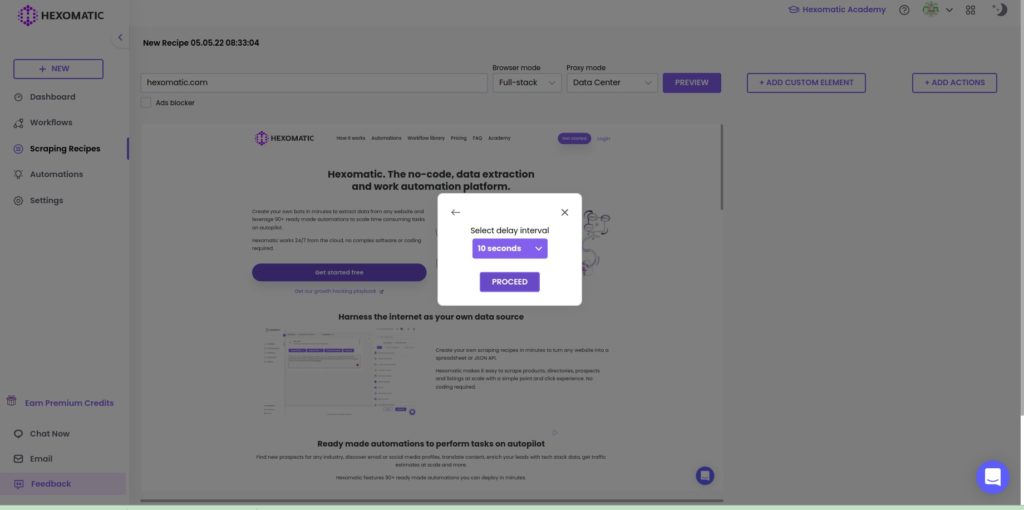
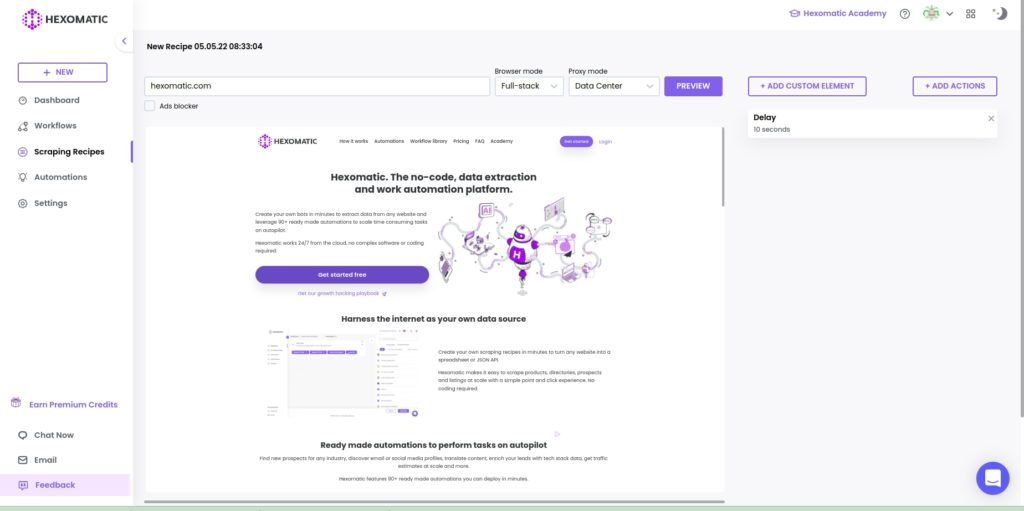
Step 2: Click proceed to update the page
After, proceeding the page will be updated, and you can select the elements to scrape and save the results.
How to use the refresh action

Some pages may need a page refresh to fully load, if this is the case you can use the refresh custom action which works just like your own web browser.
After adding the URL of the web page you want to scrape, you can easily refresh it by clicking the refresh action in the pop-up window.
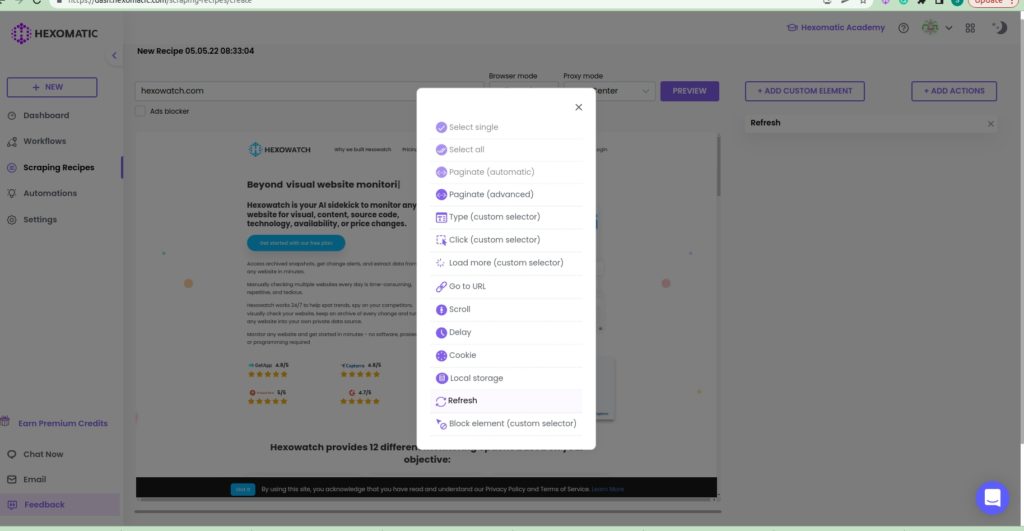
How to use the block elements action

Sometimes a page may contain pop-ups, ads or page sections obscuring your page preview. Yo
In this section, we will demonstrate how to block specific elements in the scraping recipe builder.
Before starting, note that this option is enabled only for the Full-stack browser mode.
How to block elements using point-and-click
You can block unwanted elements by using the point-and-click option right in the scraping recipe builder.
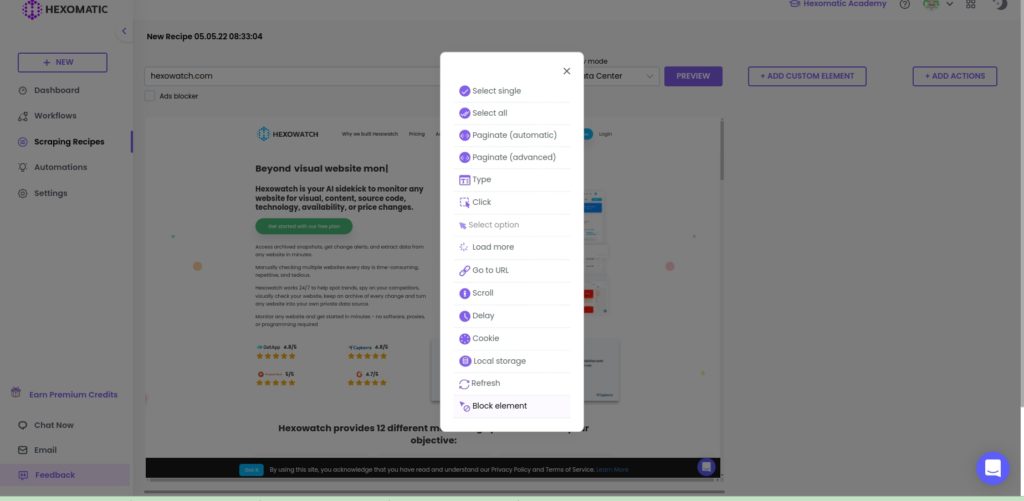
Step 1: Perform the block element action
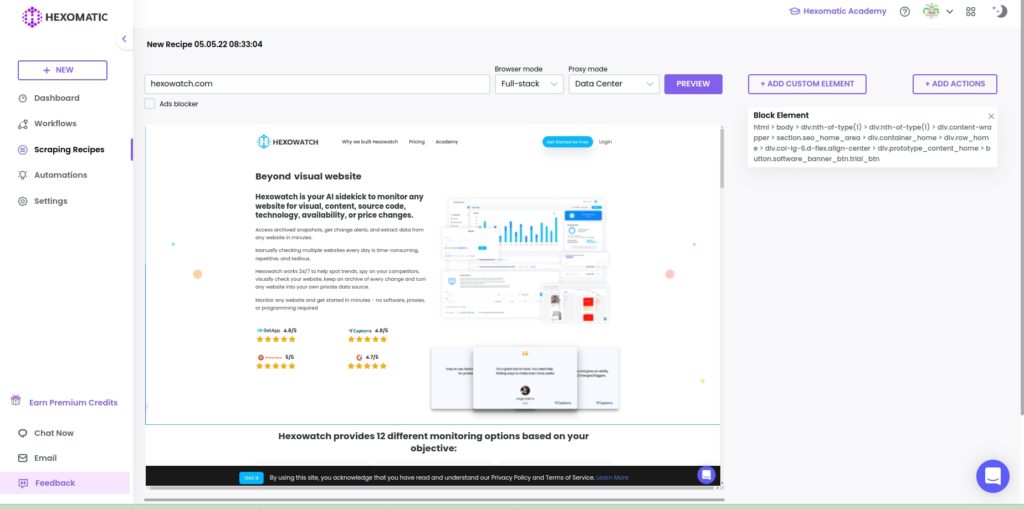
To do that, click on the element you want to block and perform the block element action.
The page will then reload without this specific page element.
How to block elements using Xpath or CSS selectors
When it is impossible to block elements using the point-and-click option in the scraping recipe builder, you can do it using the XPath/selector of the unwanted element.
Step 1: Use block element custom action
To select the element to block, you should go to the website you want to scrape with your desktop web browser, for example Chrome and inspect it. Then, choose the element you want to block, copying its XPath/selector.
Next, go to the Hexomatic scraping recipe builder, click Add Actions and choose Block element (custom selector). After this action, a pop-up window will appear. Paste the copied element Xpath/selector. Then, click Proceed.
How to use specific local storage

In this section, we will show you how to use a specific local storage item to perform an action in the scraping recipe builder.
Please note, that before using this action, you should have information on how the website to be scraped uses a specific local storage item to perform an action.
For example, you can use this action to close a pop-up, which is impossible to close by using the point-and-click action.
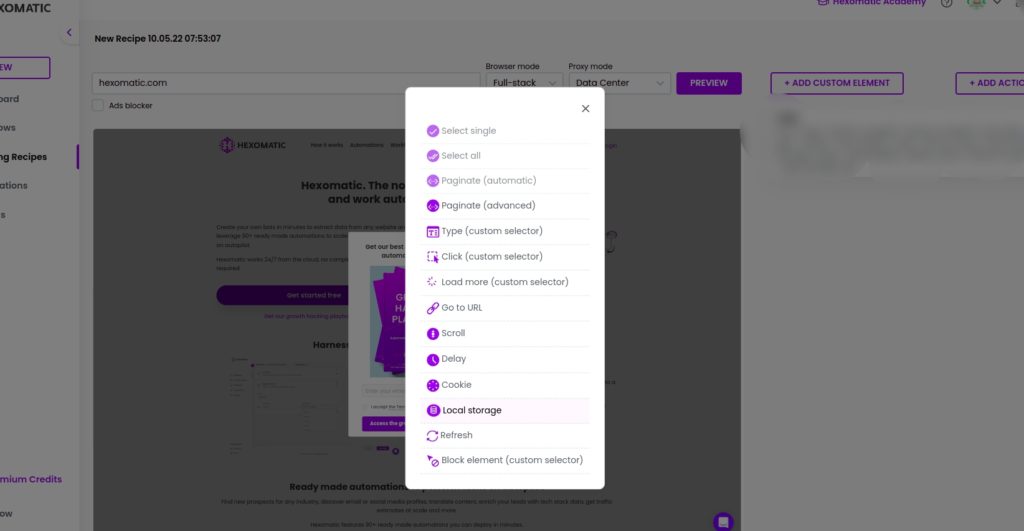
Step 1: Select local storage from “Custom actions”
After loading the website to scrape, and setting Full-stack as the browser mode, select local storage from the custom actions list. After selecting, a pop-up window will appear.
Step 2: Get the local storage key and value from the website
Go to the website you want to scrape and click Inspect. Go to Applications and click Local Storage. Choose hexomatic.com and copy the Key and the Value of the given local storage item.
Step 3: Insert the key and the value
Next, you should paste the Key and the Value of the given local storage item into the appropriate fields in the pop-up window. Then, click Proceed.
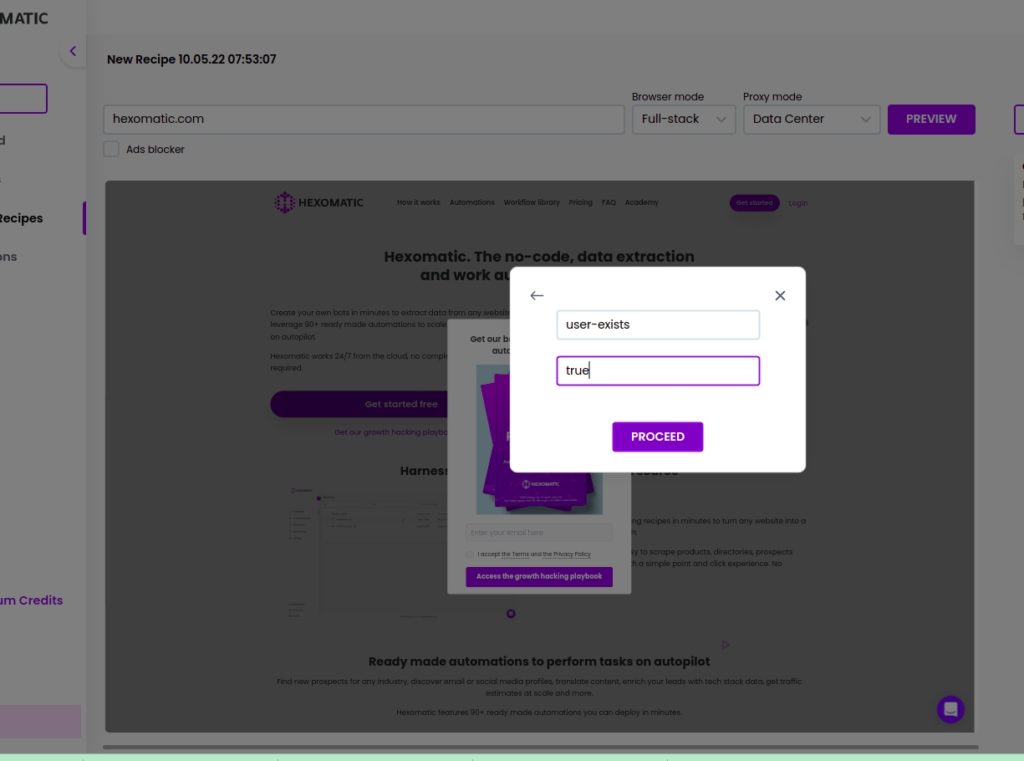
After proceeding, the pop-up will be closed.
How to set cookies manually using a custom action

Cookies were designed to be a reliable mechanism for websites to remember stateful information, such as items added to the shopping cart in an online store, or to record the user’s browsing activity. They can also be used to remember arbitrary pieces of information that the user previously entered into form fields, such as names, addresses, passwords, and credit cards.
In this section, we will demonstrate how to use cookies to perform a specific action in the scraping recipe builder of Hexomatic borrowing the session cookie from your desktop web browser.
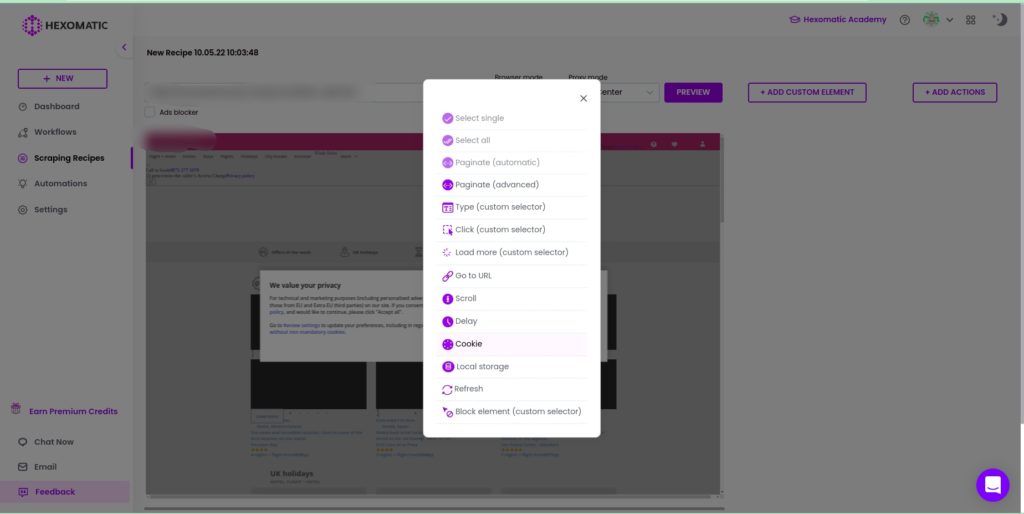
Step 1: Select Cookies from “Custom actions”
After loading the website to scrape, setting Full-stack as the browser mode, select Cookies from the custom actions list.
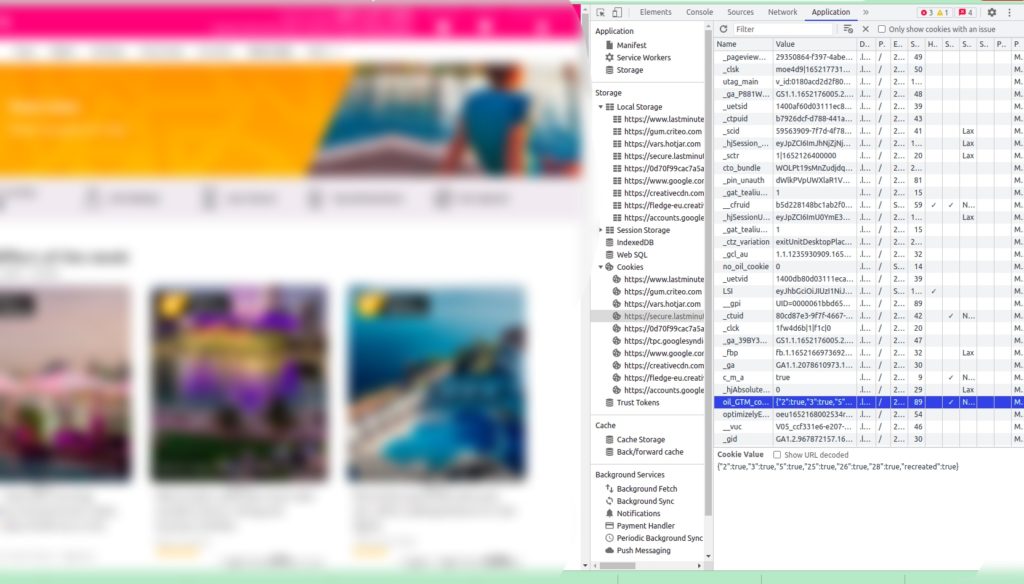
Step 2: Go to the website to scrape and get the cookie name, value, and domain
Next, go to the website you want to scrape and copy the cookie name, value, and domain.
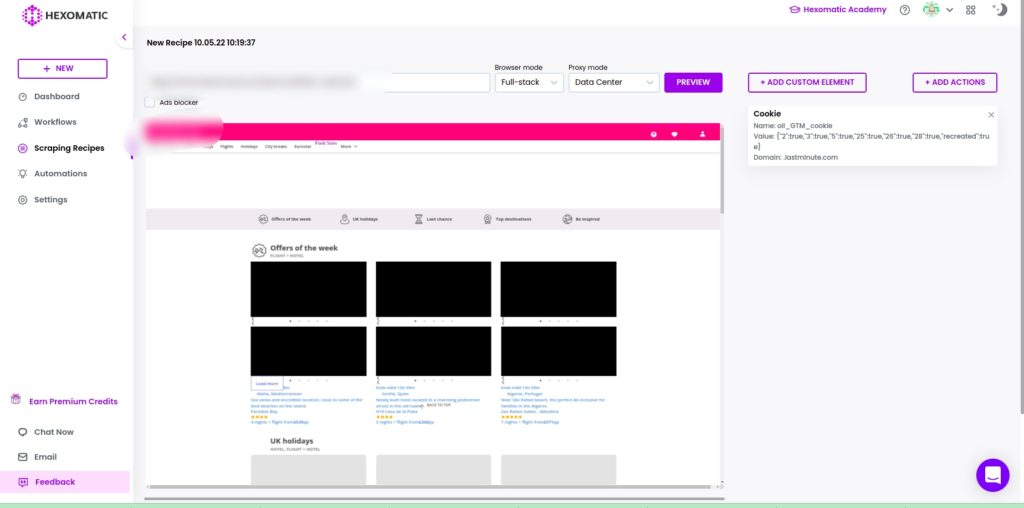
Step 3: Insert the Cookie name, value, and domain into the appropriate fields in scraping recipe
Next, go back to the scraping recipe builder and paste the copied cookie name, value, and domain in the appropriate fields. Then, click proceed to close the pop-up.
After proceeding, the pop-up will disappear, and you can select the items to scrape.
Automate & scale time-consuming tasks like never before
Marketing Specialist | Content Writer
Experienced in SaaS content writing, helps customers to automate time-consuming tasks and solve complex scraping cases with step-by-step tutorials and in depth-articles.
Follow me on Linkedin for more SaaS content