
A document, consisting of scanned images of text is difficult to access since the content of the document is images, not searchable text.
The problem is that users cannot select or resize the text nor can they change or copy it.
Turning the PDF to text will allow for the text part to be accessed separately.
In addition, getting text from images (for example, photographed menus, or scanned documents) requires manual transcription.
This problem can also be easily solved by extracting the text from images using Hexomatic.
This short tutorial will guide you through extracting text from PDF documents or images at scale in just a few clicks using Hexomatic.
Step 1: Create a new workflow
From your dashboard, create a new workflow by choosing the “blank” option. Then, select Data automation as a starting point.
Step 2: Upload files
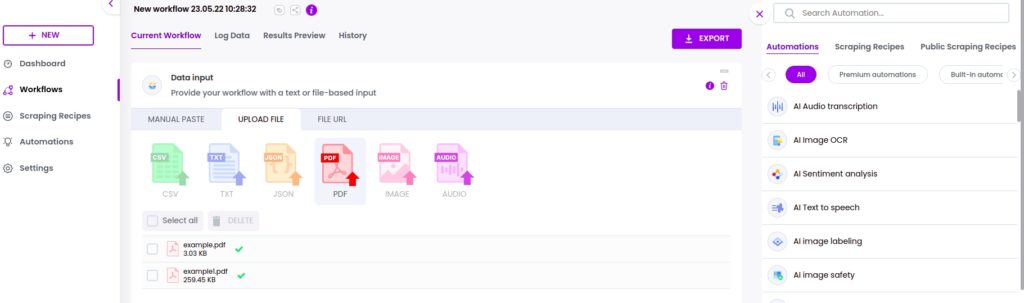
Next, choose the Upload file option and browse the files (PDF, IMAGE) to extract text from. In this case, we upload PDF files.
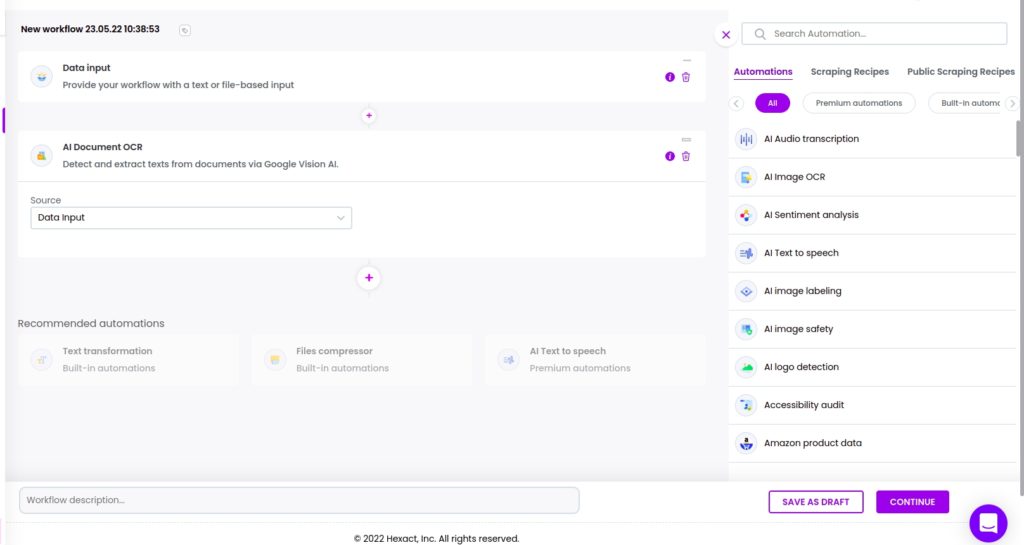
Step 3: Add the AI document OCR automation
Add the AI document OCR automation, selecting data input as the source.
Then, click Continue.
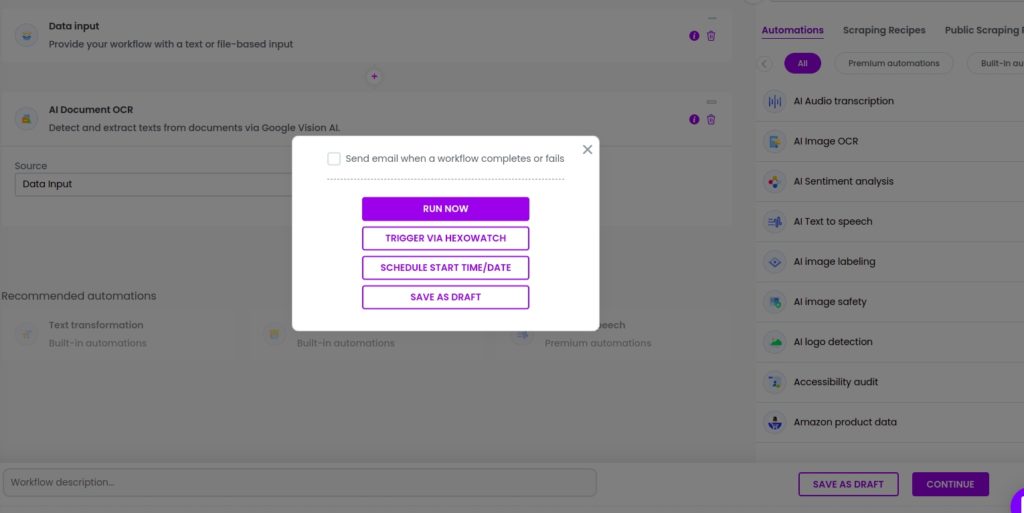
Step 4: Run or schedule the workflow
You can click Run now to run the automation or schedule it.
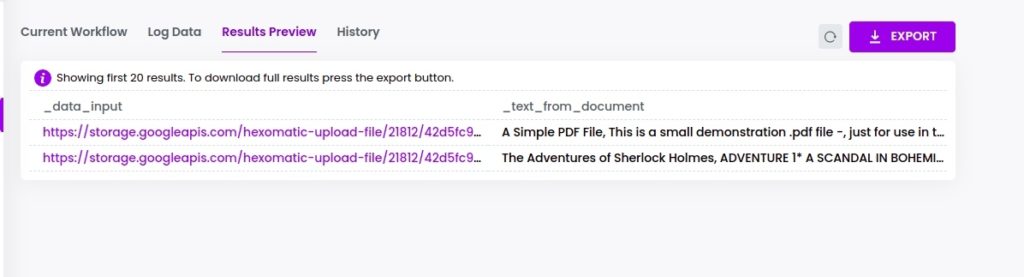
Step 5: View and save the results
Once the workflow has finished running, you can view the results and export them to CSV or Google Sheets.
Automate & scale time-consuming tasks like never before
Marketing Specialist | Content Writer
Experienced in SaaS content writing, helps customers to automate time-consuming tasks and solve complex scraping cases with step-by-step tutorials and in depth-articles.
Follow me on Linkedin for more SaaS content