Indeed is the largest job posting website in the US, Canada, and the world with 225 million resumes. Indeed also happens to be a goldmine for recruiters, companies, and job seekers wanting to tap into their data. But collecting this data manually is time-consuming.
In this tutorial, we will show you how to scrape Indeed job listings from different pages at scale using Hexomatic.
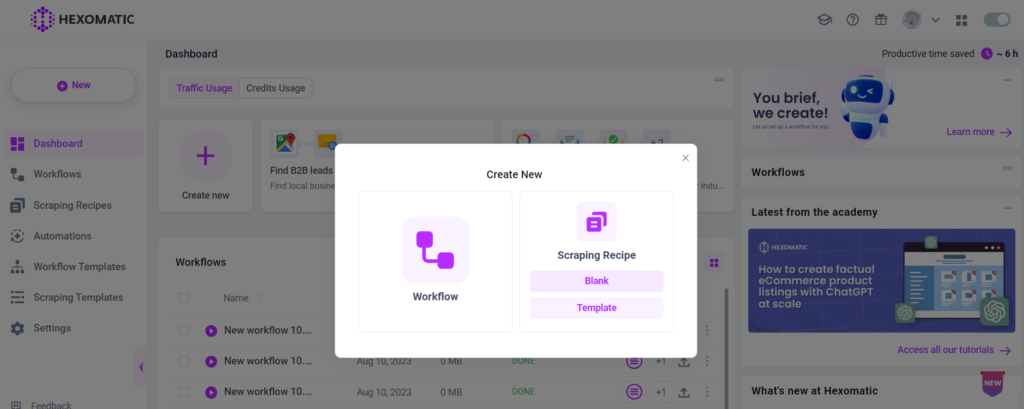
Step 1: Create a new scraping recipe
Go to your dashboard and create a blank scraping recipe.
Step 2: Add the web page URL
Add the web page URL.
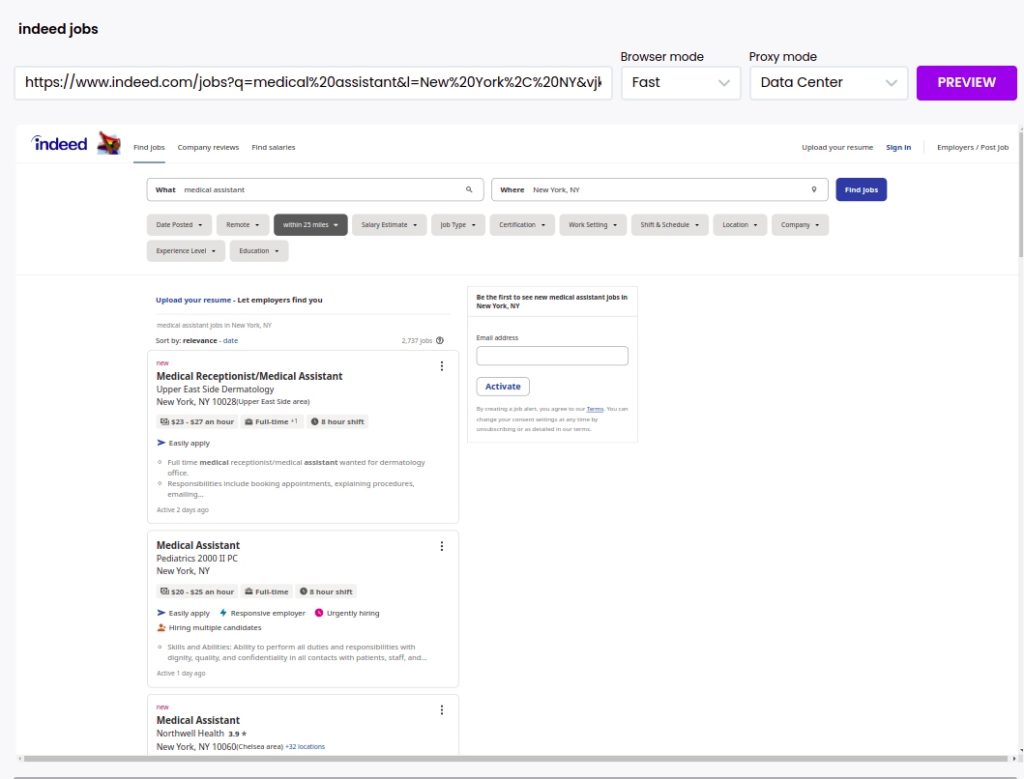
Step 3: Select elements to scrape
Once the page has loaded, click on any element you want to capture.
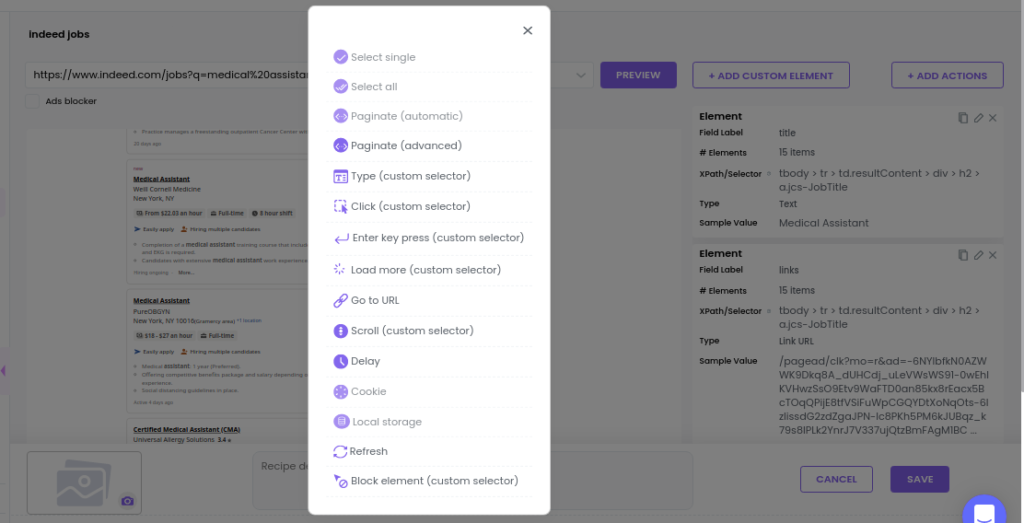
Step 4: Scrape data from more pages
As only a small amount of data is displayed on the first page, you need to go to the next pages to scrape more data.
You can use pagination to automatically scrape data from the next pages.
Use advanced pagination
Here, we will use the Advanced pagination, using Gap option to scrape the data from the next pages automatically.
Step 1: Go to the website
Open the targeted web page in your browser and get to the 2nd page of the job listing and capture it.
Step 2: Select Advanced pagination action
Go back to the scraping recipe builder and add the advanced pagination action.
Step 3: Add the URL and page number
In the popup window, paste the captured URL.
Put the page numbers you’d like to paginate. As the pages are displayed in gaps, you need to use the Gap option of Advanced pagination.
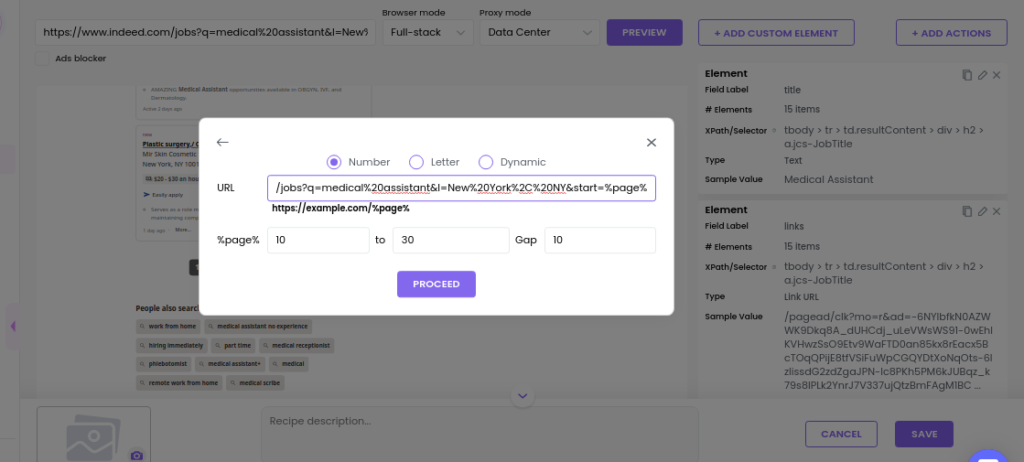
Then, click Proceed.
Step 3: Save the recipe
Click Save to complete the scraping process.
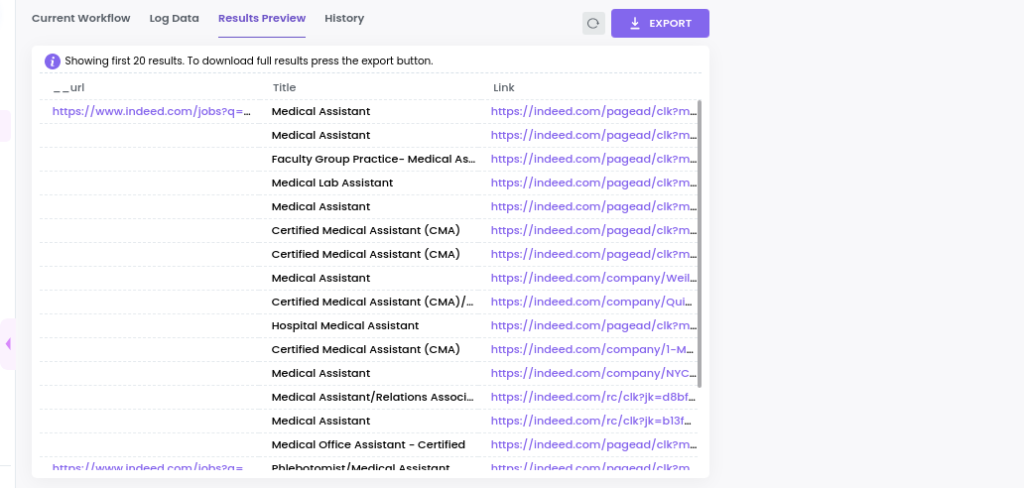
If you run this scraping recipe in a workflow, you will get the results like this:
Automate & scale time-consuming tasks like never before
Marketing Specialist | Content Writer
Experienced in SaaS content writing, helps customers to automate time-consuming tasks and solve complex scraping cases with step-by-step tutorials and in depth-articles.
Follow me on Linkedin for more SaaS content