
As of 2022, the number of internet users worldwide has risen to almost 5 billion, a staggering increase of 192 million within one year.
According to internet live stats, there are over 1.5 billion websites on the world wide web today.
If you want to capture data from these websites, you have to dig into the HTML which is a treasure trove of information.
For example, you can scrape HTML to collect product and pricing data, company data, and more. In fact, search engines use scrape HTML to curate and improve their search results by collecting data from various websites.
The fastest and easiest way to get the HTML of a website is by using an HTML scraping tool that requires no coding or technical skills.
The good news is that Hexomatic can capture the HTML from websites in bulk literally in a few minutes.
Let’s dive in.
To get started, you need to have a Hexomatic.com account.
Step 1: Create a new workflow
Go to your dashboard and create a new workflow by choosing the “blank” option. Select the Data input automation as your starting point.
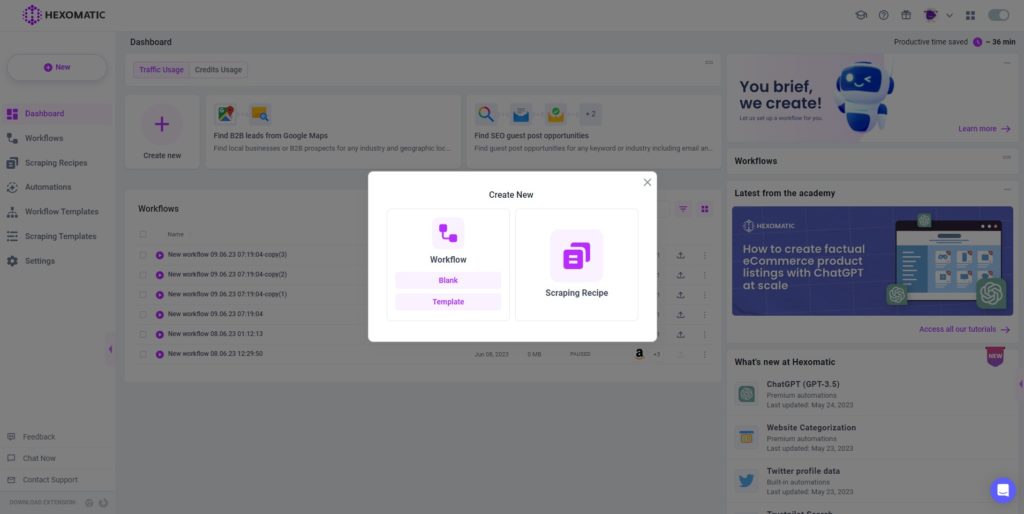
Step 2: Add the website URLs
Next, insert the targeted website URLs using the Manual paste/list of inputs option.
You can add a single URL or URLs in bulk.
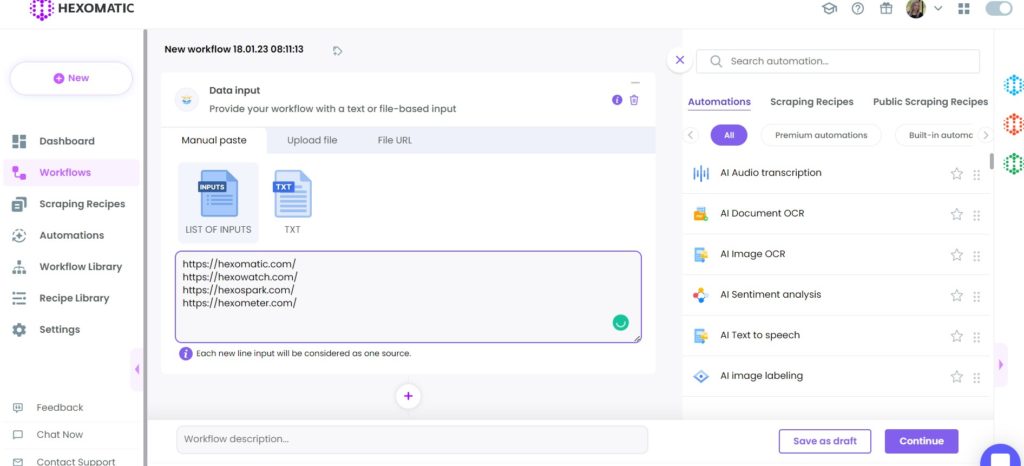
Step 3: Add the HTML grabber automation
Next, add the HTML grabber automation of Hexomatic, selecting data input as the source.
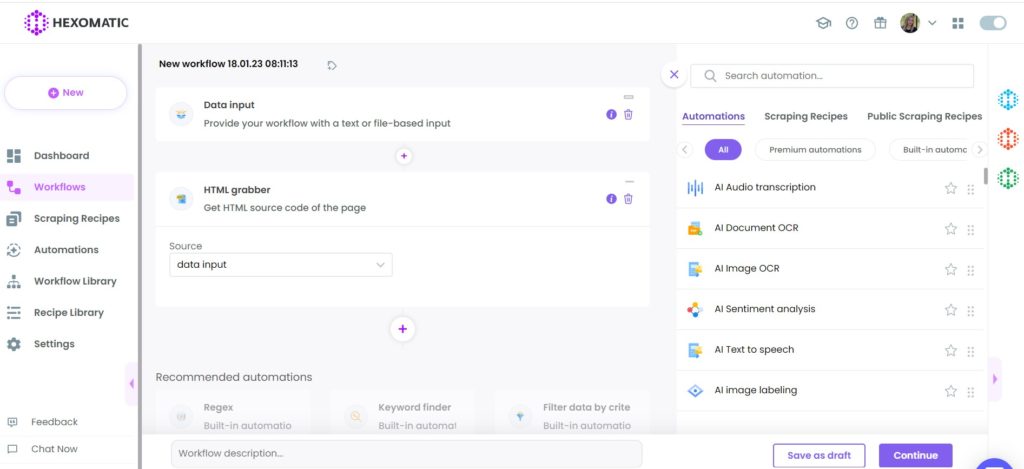
Step 4: Run the workflow
You can click Run now to run the workflow or schedule it.
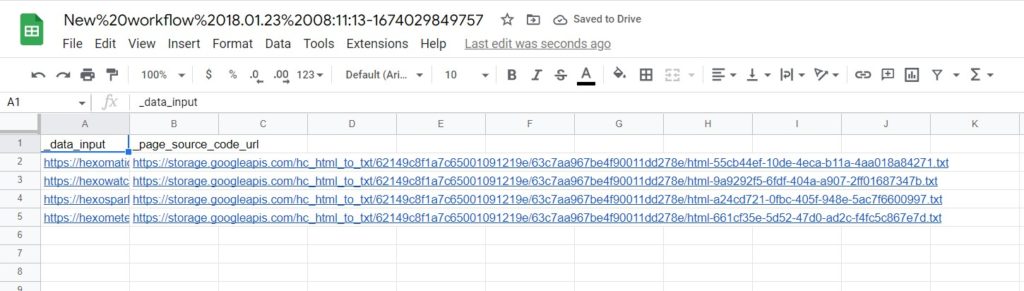
Step 5: View and save the results
Once the workflow has finished running, you can view the results and export them to CSV or Google Sheets.
Automate & scale time-consuming tasks like never before
Marketing Specialist | Content Writer
Experienced in SaaS content writing, helps customers to automate time-consuming tasks and solve complex scraping cases with step-by-step tutorials and in depth-articles.
Follow me on Linkedin for more SaaS content