
Directory websites are a great source for generating B2B leads in almost any industry. They can help you find thousands of targeted leads based on different search criteria.
These types of websites are ideal for in-depth research, competitor analysis, getting in touch with or finding qualified professionals or businesses in any industry.
For instance, imagine you sell a product or service and your best clients are wedding photographers.
If you try and research and capture this data manually by copy-pasting the contacts of wedding photographers, it will take you hours! You have to visit multiple websites and add the required information to your excel sheet or CRM, and I’m sure you have higher-value tasks to do in the day.
With Hexomatic, you can scrape this type of data in minutes without any coding or software required.
Here’s what you are going to learn in this tutorial:
Before starting, make sure you have a Hexomatic account. If you haven’t got one yet, head to https://hexomatic.com.
#1 How to scrape page URLs from a directory website
For this example we are going to capture all the pages from this wedding photographer directory:
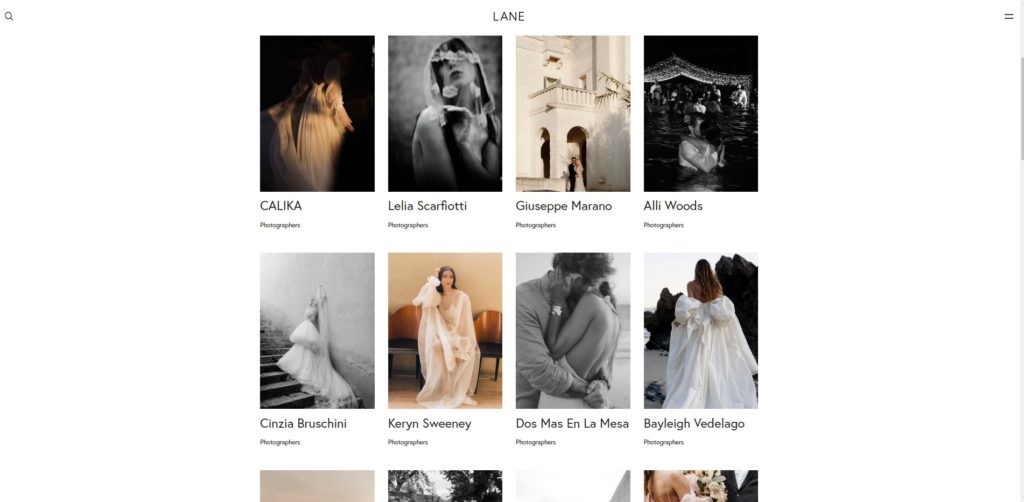
This will enable us to capture all the wedding photographers and their profile pages.
Let’s start the process by scraping page URLs from a category page.
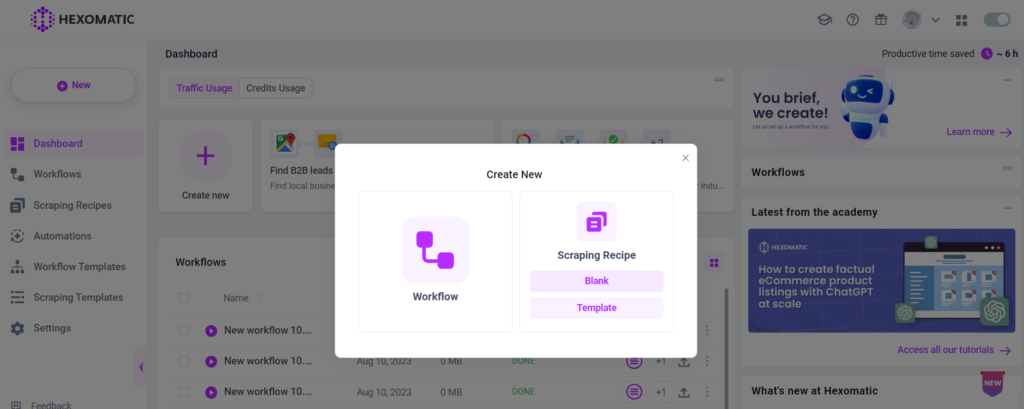
1. Create a new scraping recipe
Create a new blank scraping recipe.
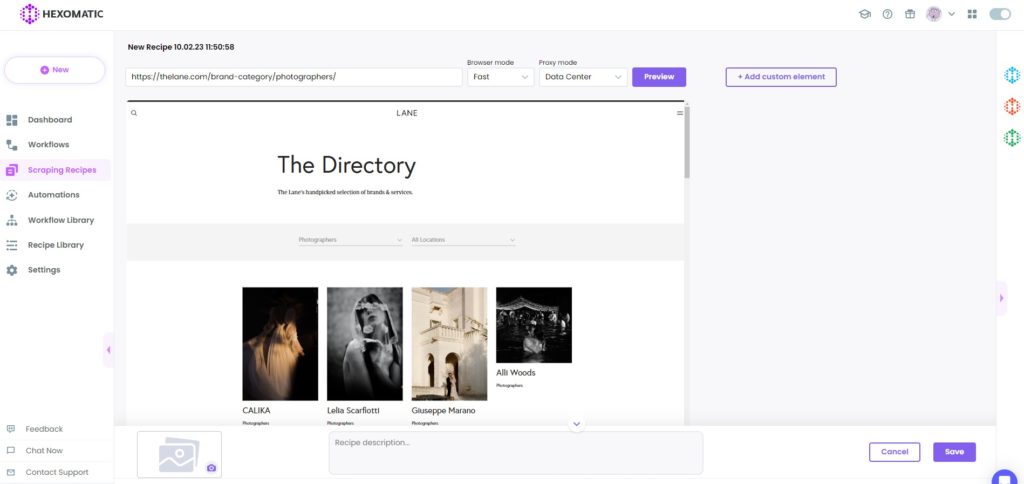
2. Add the web page URL
Add the web page URL of wedding photographers’ listings and click Preview.
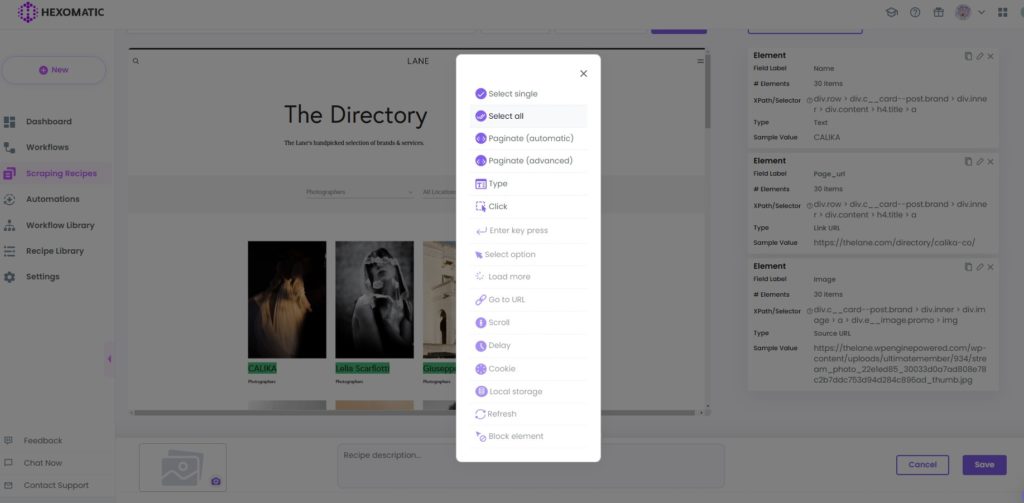
3. Select elements to scrape
Now you can choose the elements for scraping. In this case, we are going to scrape URLs. To do it select the first photographer’s name and choose the Select all option to capture all the elements in the same category.
Select Link URL as the element type. Then click on the Save button to save the recipe.
We can now run this scraping recipe in a workflow to get the list of photographers in a spreadsheet or Google sheet, or we can create a second scraping recipe first which will capture each individual profile. For this example, we will create a second scraping recipe.
#2 How to scrape detailed page data
Now we have a scraping recipe, which will capture the URLs of all the photographer profiles. We can now create another recipe, which will capture detailed profile data for each photographer.
1. Create a new scraping recipe to capture individual listings
Now, go to the dashboard again and create another scraping recipe for a specific photographer listing.
For example, we will use this profile page for scraping:
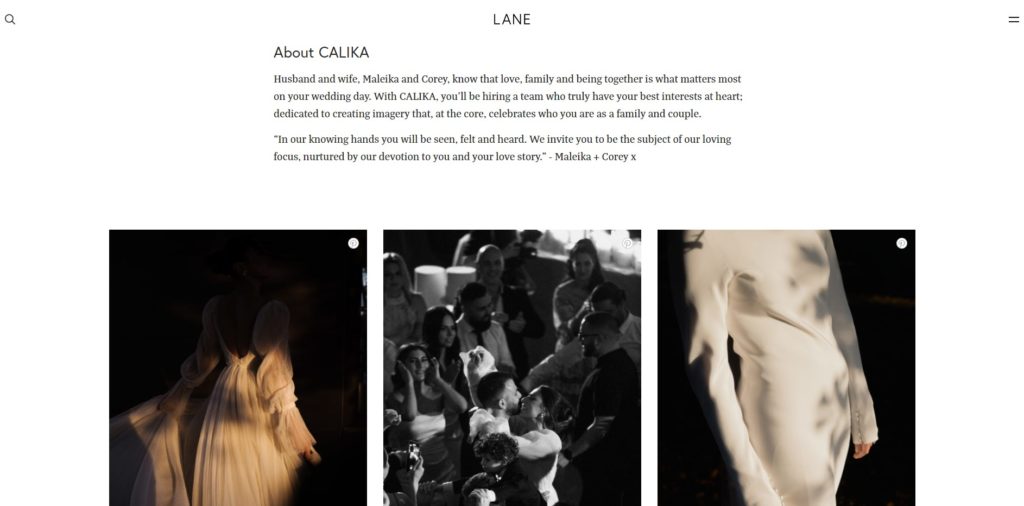
2. Add the web page URL
Add the webpage URL of the individual photographer and click Preview.
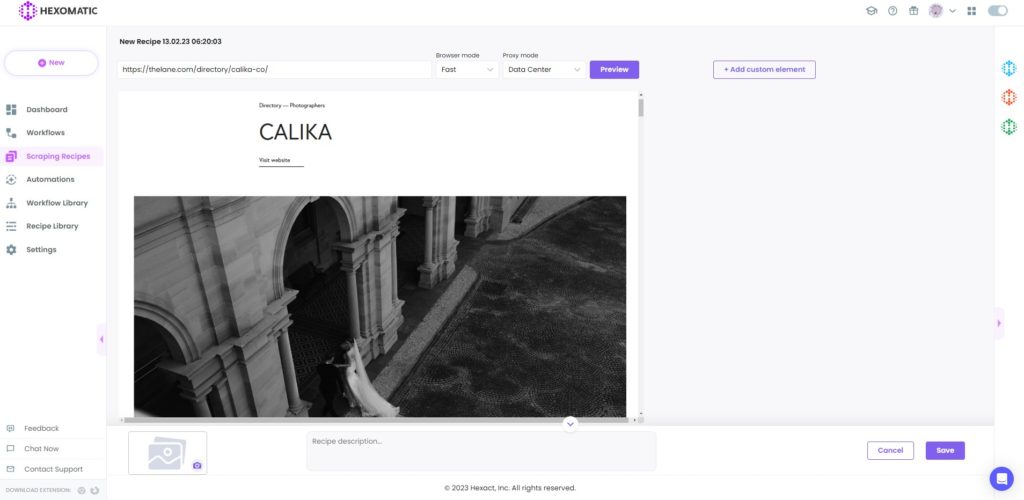
3. Select elements to scrape
Now, choose the required elements for scraping. In this case, we will select the photographer’s name and choose the Select single option.
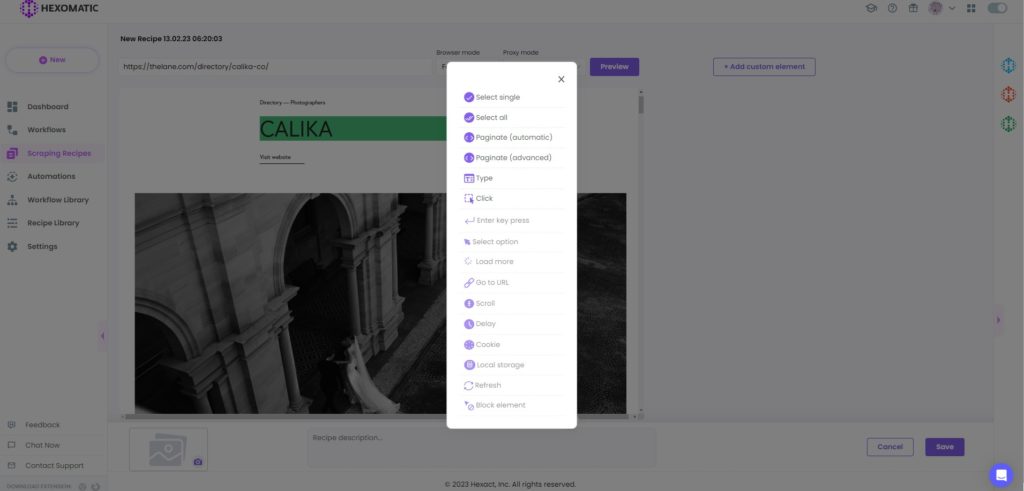
Next, choose the Text as the element type and save it.
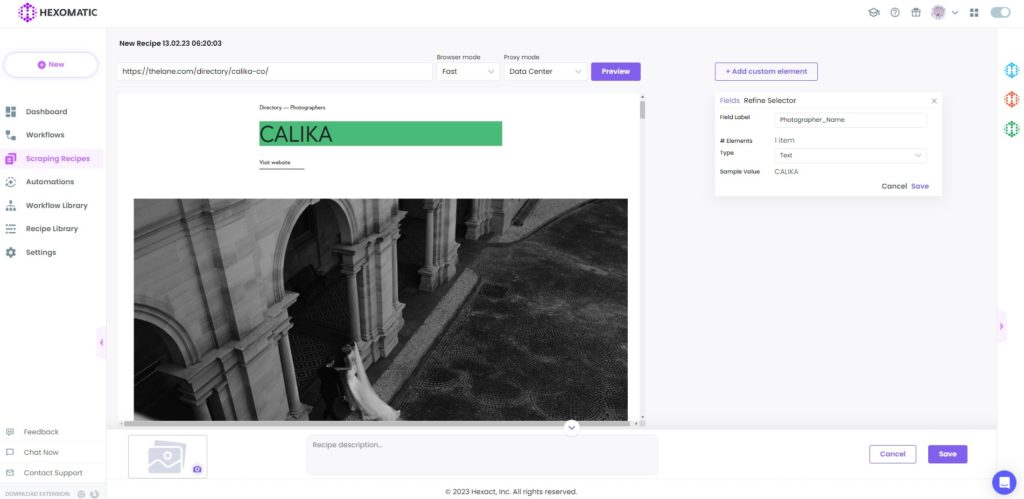
You can also choose the image with the Source URL type. Then the phone number with the number type and the About section with the Text type. You should choose the Select single option for all these elements.
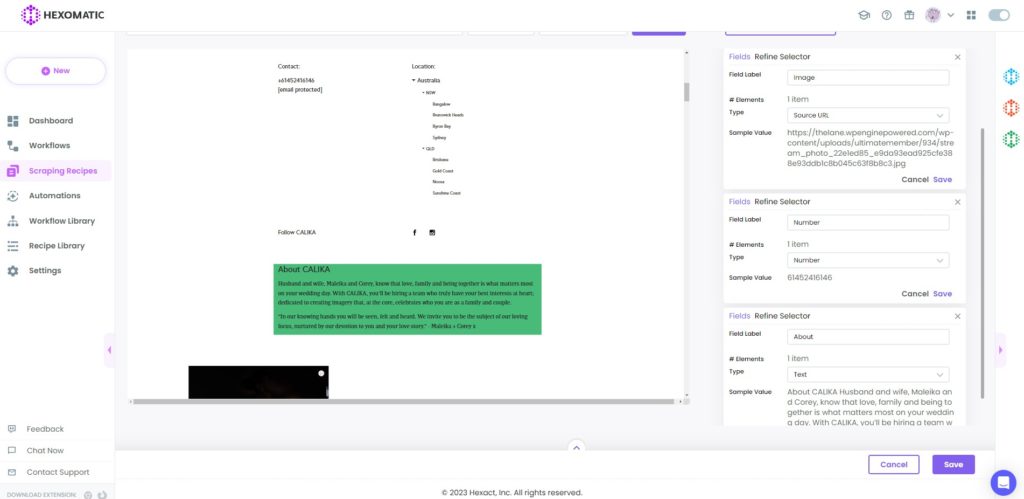
#3 How to combine 2 recipes to scrape data from a list of URLs
Once you have saved both scraping recipes, it’s time to combine them to scrape data from a list of URLs automatically. This is a great option to capture the profile data for every photographer with one workflow.
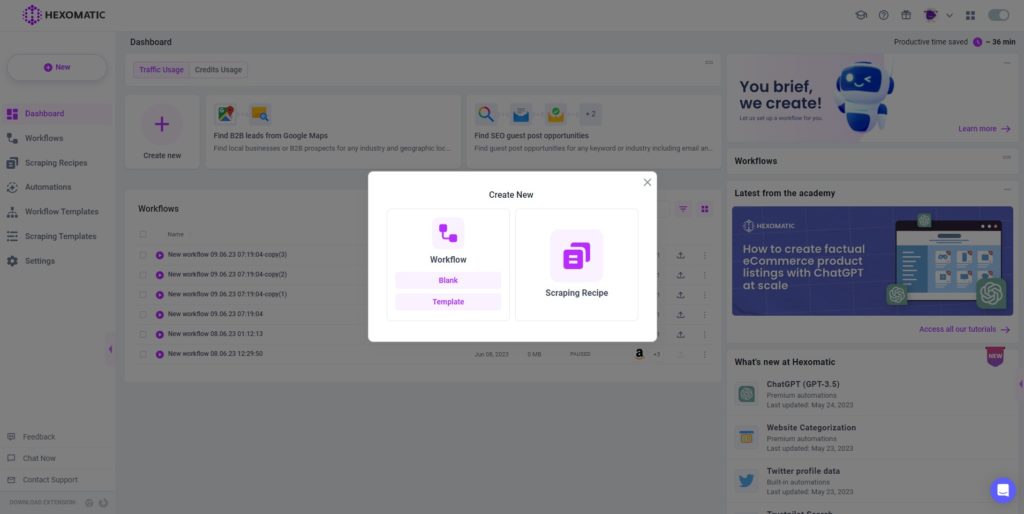
1. Create a new workflow
Go back to your dashboard and create a new blank workflow.
2. Add the first scraping recipe
Add the first recipe you’ve created, covering the list of URLs. You can find the recipe on the right side of the screen.

3. Add the second scraping recipe
Now, add the detailed page recipe, choosing Page URLs as the source.
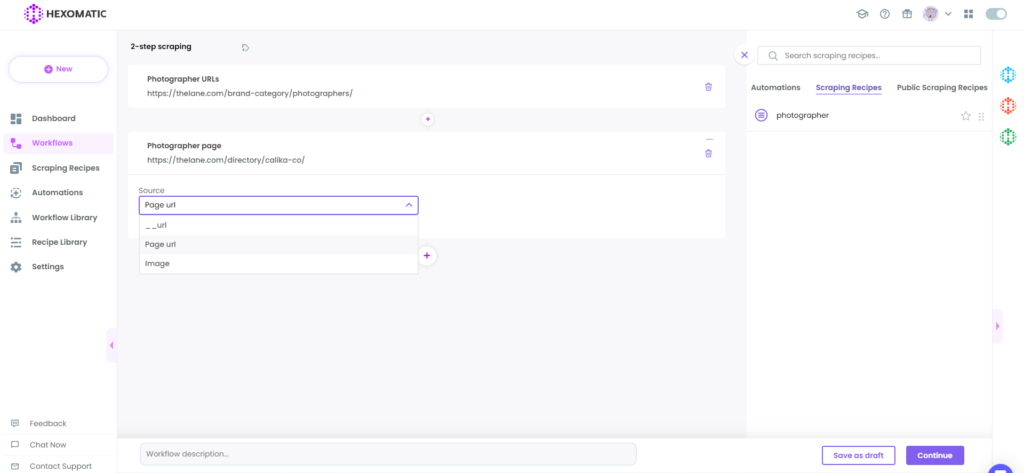
After choosing both scraping recipes, click on Continue.
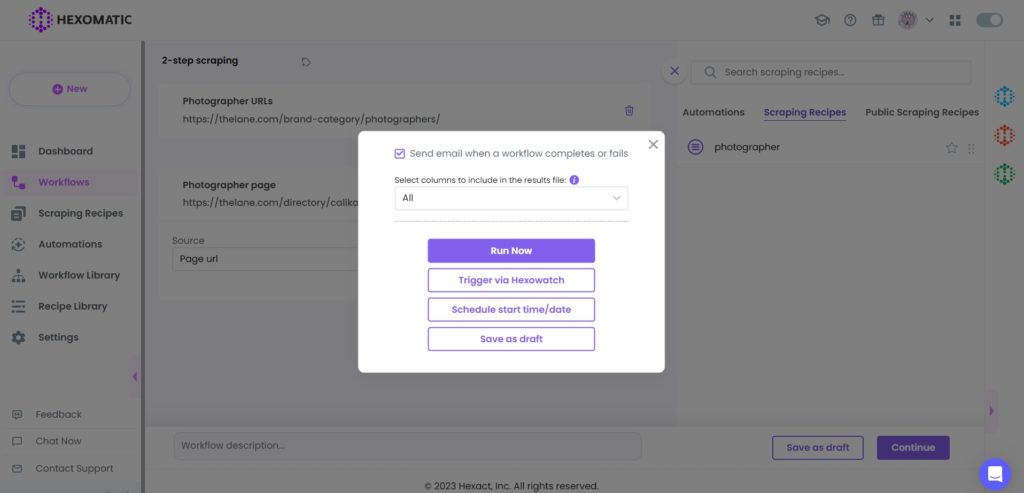
4. Run the workflow
Next, run your workflow by clicking on the Run Now button.
5. View and save the results
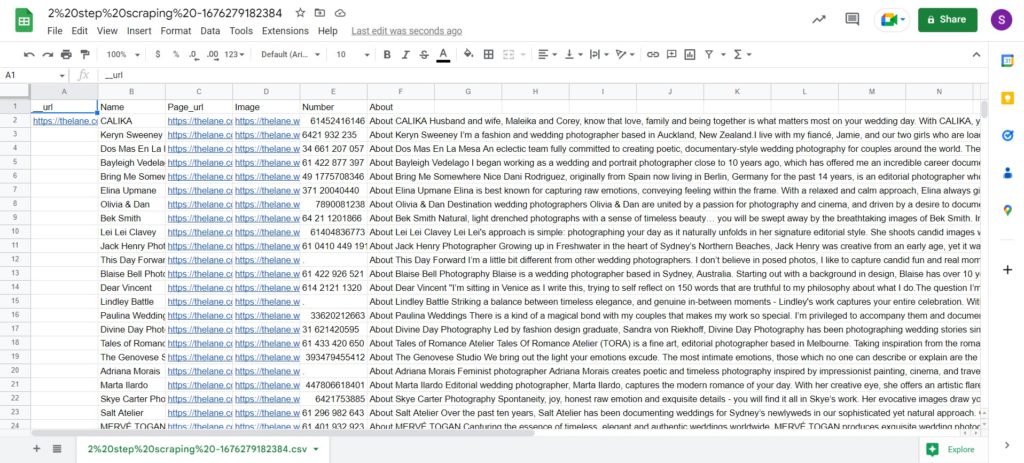
Once the workflow has finished running, you can view the results and save them to CSV or Google Sheets.
Here you will see the URL of each profile captured, as well as all the fields we extracted from every single profile.
Automate & scale time-consuming tasks like never before

Content Writer | Marketing Specialist
Experienced in writing SaaS and marketing content, helps customers to easily perform web scrapings, automate time-consuming tasks and be informed about latest tech trends with step-by-step tutorials and insider articles.
Follow me on Linkedin