GitHub is a web-based platform for version control and collaboration that uses Git as its underlying technology.
Over 80 million developers use GitHub to store their code, track changes, and collaborate with other developers on projects. It also provides features such as bug tracking, feature requests, task management, and wikis for every project.
Additionally, it has a large open-source community and is widely used for open-source software development.
Scraping data from GitHub can be helpful for a variety of purposes, such as:
👉 Gathering information about projects and their contributors
👉 Analyzing trends in programming languages and technologies
👉 Identifying potential collaborators or job candidates
👉 Researching code examples for a specific topic or problem
👉 Monitoring the activity of competitors or open-source projects, and many more.
In this tutorial, we will show you the easiest way of scraping data from GitHub with Hexomatic.
No need to write even a single line of code, just add the page URLs, and Hexomatic will return you the desired data in minutes.
You will specifically learn:
#1 How to scrape GitHub topic listings
#2 How to scrape a single GitHub topic page
To get started, you need to have a Hexomatic.com account.
#1 How to scrape GitHub topic listings
First and foremost, let’s see how you can scrape all the GitHub topic listings on a page, including the topic names, descriptions, and URLs.
In the second part, we will learn how to scrape detailed data from each of the topic pages to have a complete data sheet.
Follow the simple steps below to get things done.
Step 1: Go to the Library of Scraping Templates
From your dashboard, select Scraping Templates to access the public scraping recipes.
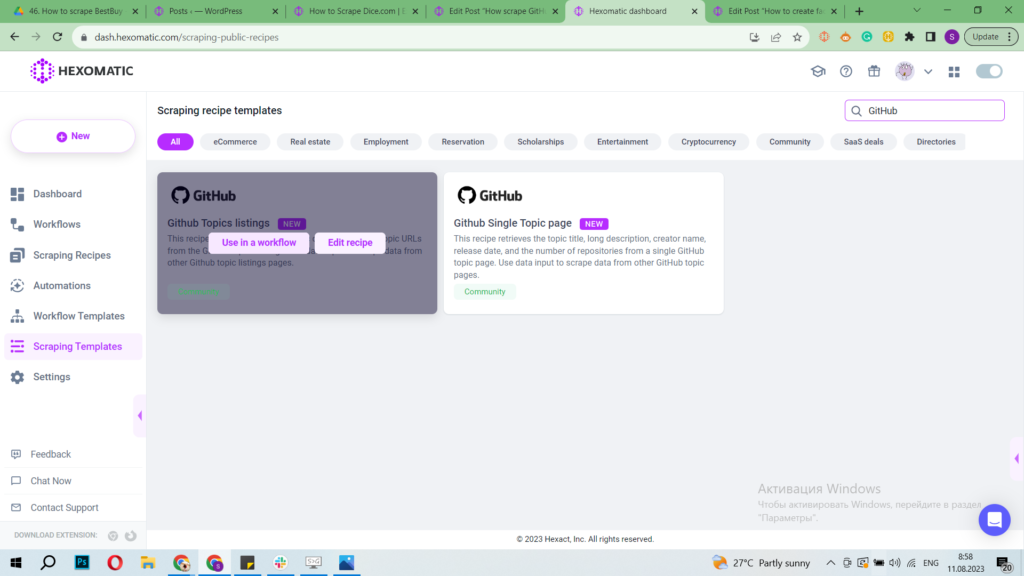
Step 2: Use the “GitHub Topics Listings” recipe in a workflow
From the Scraping Templates, choose the “GitHub Topics Listings” recipe and select the “Use in a workflow” option.
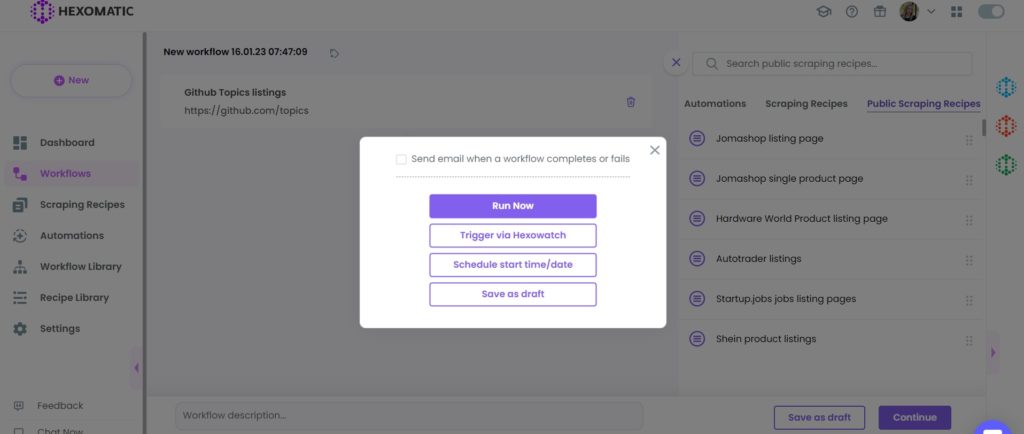
After clicking “Use in a workflow”, your workflow will be created. Next, click Continue.
Step 3: Run the workflow
Now, you can run your workflow by clicking “Run now”.
Step 4: View and save the results
Once the workflow has finished running, you can view the results and export them to CSV or Google Sheets.
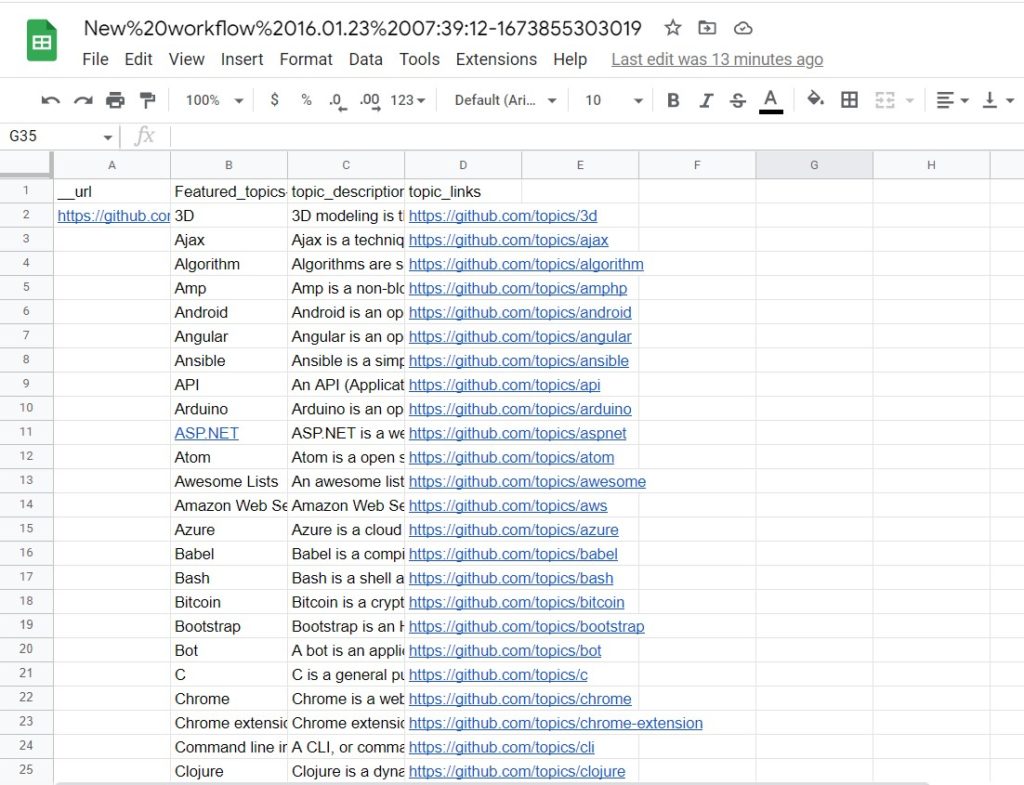
So, we learned how to automatically scrape all the topic listings on a page.
Additionally, If you want to get the rest of the listings from GitHub, you need to make a simple tweak in our ready-made recipe.
Let’s see how to do it.
Step 1: Navigate to the “GitHub Topics Listings” recipe
From the Recipes list, choose the “GitHub Topics Listings” recipe and go inside the recipe by clicking on the Edit recipe option.
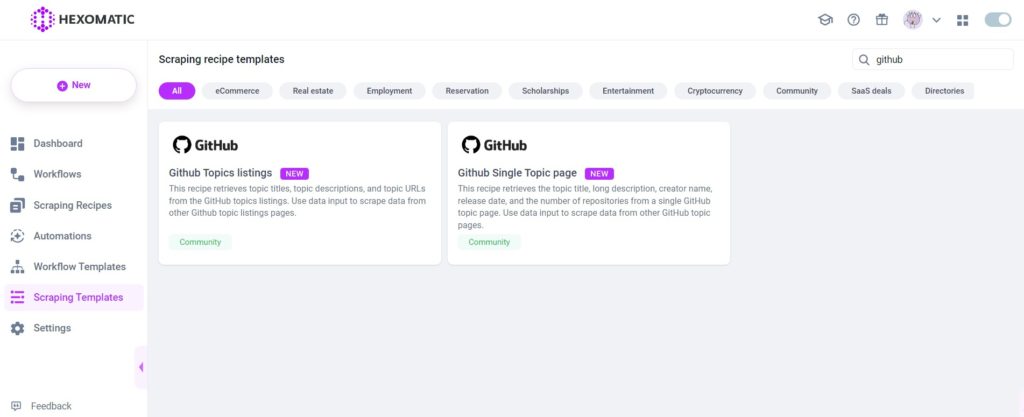
Get to the bottom of the page where you will see the “load more” button. Click on it and, choose the “Click” action.
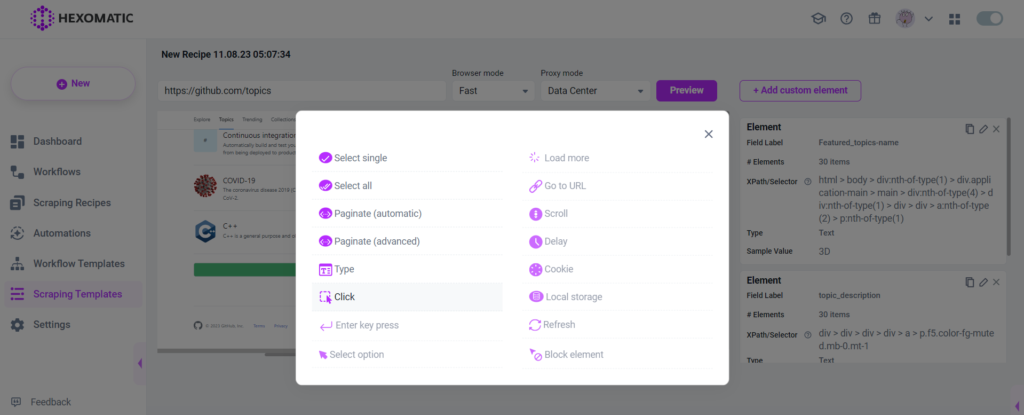
You will then be able to scrape the next 30 topics.
Select the elements (topic names, descriptions, and URLs) to scrape and save the recipe.
Use the select all option for each category, then choose the element types: Text for the topic names and descriptions, link URLs, or Source URLs for the URLs.
Repeat the same action for scraping data for each next batch of topics.
#2 How to scrape a single GitHub topic page
In this section, we will demonstrate how to automatically scrape detailed data for any GitHub topic page.
Step 1: Go to the Library of Scraping Templates
From your dashboard, select Scraping Templates to access the public scraping recipes.
Step 2: Capture the desired category page URL(s)
Go to https://github.com/topics and capture the desired topic page URL(s).
For example,
Step 3: Select the “GitHub single topic page” recipe
From the Recipe templates, select the recipe and choose the “Use in a workflow” option.
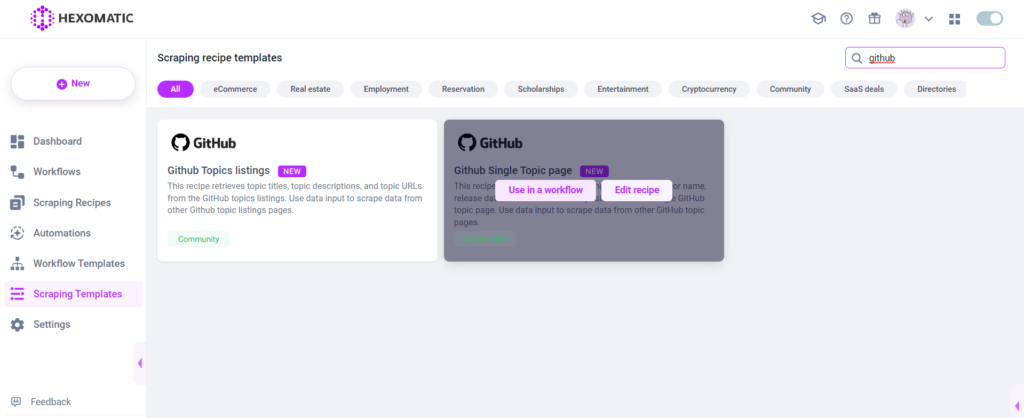
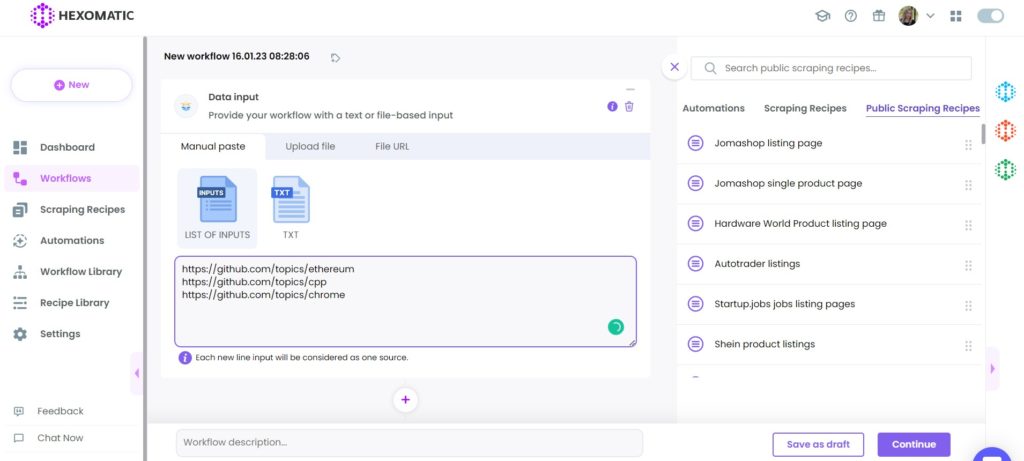
Step 4: Add the captured URL(s)
Choose the Data Input automation as your starting point and insert the previously captured URL(s). You can add a single URL or bulk URLs.
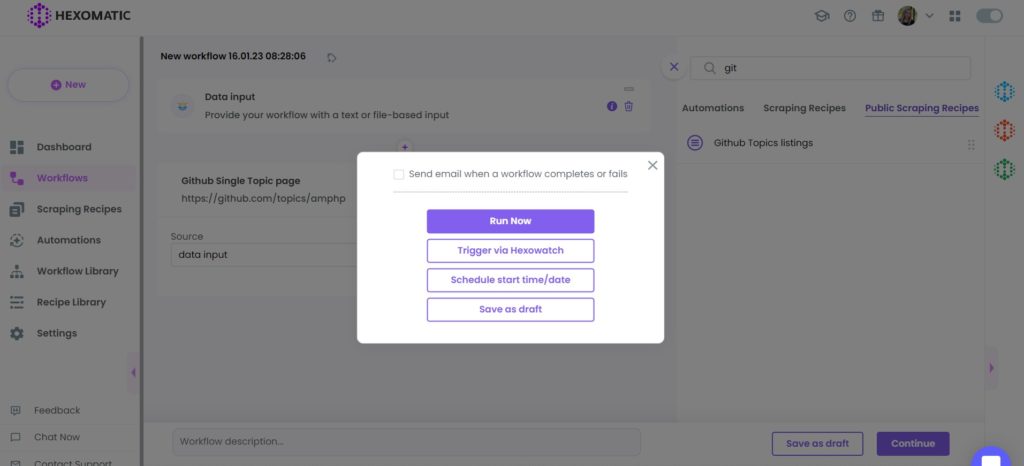
Step 5: Run the workflow
You can run the workflow by clicking “Run now”.
Step 6: View and Save the results
Once the workflow has finished running, you can view the results and export them to Google Sheets.
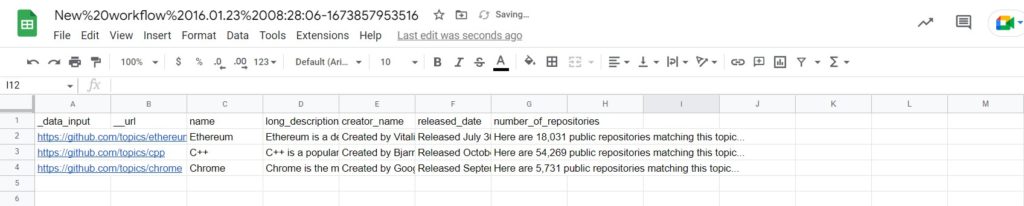
As you can see, in our Google Sheets we got detailed information, including the topic name, long description, release date, and the number of repositories for each topic we selected.
You can use this method for scraping any other topic from GitHub.
Automate & scale time-consuming tasks like never before
Marketing Specialist | Content Writer
Experienced in SaaS content writing, helps customers to automate time-consuming tasks and solve complex scraping cases with step-by-step tutorials and in depth-articles.
Follow me on Linkedin for more SaaS content