
Google AI has a powerful text-to-voice engine that allows developers to turn text to speech in seconds returning high-quality audio files for any purpose, including marketing, journalism, banking and finance, tourism, etc.
However this requires developers to use the API, and the transcribed audio sounds can sound robotic or synthetic, which can be quite problematic for some businesses that need to create emotional connections with their consumers.
The good news is that Hexomatic enables anyone to tap into Google AI text-to-speech and supports Speech Synthesis Markup Language (SSML). A markup language based on XML. It is designed for speech synthesis applications and is capable of controlling different characteristics of synthesized speech to make your audio sound more human.
For example, you can use SSML tags natively in Hexomatic to add a pause between sentences, pronounce acronyms and abbreviations, control timbre, control volume, control how special words are pronounced, and a ton more.
This tutorial demonstrates how to use SSML tags to create personalized audio from texts using Hexomatic AI Text to speech automation.
You can find the most commonly used SSML tags with examples below:
<speak> element
This is the root element of SSL documents.
For example:
<speak>
Welcome to my page
</speak>
<break> element
This element provides the ability to specify pause durations between words.
There are two possible attributes:
time – Sets the length of the break by seconds or milliseconds (e.g. “3s” or “250ms”).
For example:
<speak>
Step 1, take a deep breath. <break time="200ms"/>
Step 2, exhale.
</speak>
strength – Sets the strength of the output’s prosodic break by relative terms. Valid values are: “x-weak”, weak”, “medium”, “strong”, and “x-strong”.
For example:
<speak>
Step 3, take a deep breath again. <break strength="weak"/>
Step 4, exhale.
</speak>
<say-as> element
The given element allows indicating information about the type of text construct contained within the element. With this element, you can specify the detail level for rendering the text contained.
This element requires the attribute, interpret-as, to determine the way the value is spoken. You can also use optional attributes format and detail depending on the value.
For example,
cardinal
This example is spoken as “Eleven thousand four hundred thirty-seven”.
<speak>
<say-as interpret-as="cardinal">11437</say-as>
</speak>
ordinal
This example is spoken as “Third”.
<speak>
<say-as interpret-as="ordinal">3</say-as>
</speak>
verbatim (spell-out)
This example is spelled out letter by letter:
<speak>
<say-as interpret-as="verbatim">abcdefg</say-as>
</speak>
date
Supported field character codes for year, month, and day are {y, m, d}. If the field code appears once for a year, month, or day.
You can separate the fields in the date text by spaces and punctuation.
For example:
This example is spoken as “The third of March, nineteen ninety-one”.
<speak>
<say-as interpret-as="date" format="yyyymmdd" detail="1">
1991-03-03
</say-as>
</speak>
This example is spoken as “The third of March”.
<speak>
<say-as interpret-as="date" format="dm">3-3</say-as>
</speak>
This example is spoken as “March third, nineteen ninety-one”.
time
The following example is spoken as “Three forty P.M.”
<speak>
<say-as interpret-as="time" format="hms12">3:40pm</say-as>
</speak>
<p>,<s>
Sentence and paragraph elements.
For example
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
<emphasis> element
This element is applied for adding or removing emphasis from the text. Please note that these tags must be used merely around a full sentence not to cause unwanted pauses in the speech.
The following values are supported by the <emphasis> element:
strong
moderate
none
reduced
For example:
<emphasis level="moderate"> We are excited to announce the launch of our new product</emphasis><par> element
A parallel media container enables playing multiple media elements simultaneously. Allowed content includes a set of 1 or more <par>, <seq>, and <media> elements.
For example:
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6db">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media> element
Represents a set of <par> or <seq> elements. The allowed content of this eement is <speak> or <audio>.
Follow the steps below to learn how to use SSML tags to create personalized audio from texts using Hexomatic AI Text to speech automation.
Step 1: Create a new workflow
Go to your dashboard and select AI Text to Speech automation from the automation section.
Step 2: Add the text
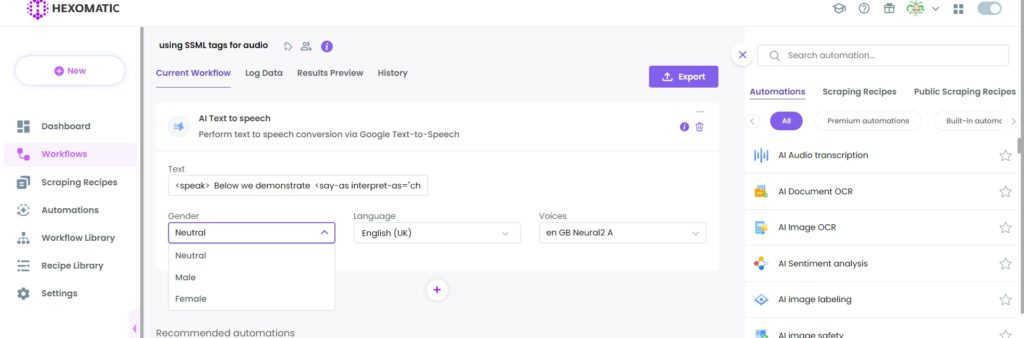
Next, add the text you want to convert to audio using SSML tags. Here is an example:
<speak>
Below we demonstrate <say-as interpret-as="characters">SSML</say-as> samples.
You can pause <break time="3s"/>.
You can use it for speaking in cardinals. The number is <say-as interpret-as="cardinal">11</say-as>.
Also, you can use it for speaking in ordinals. I am <say-as interpret-as="ordinal">11</say-as> in line.
You can use it for speaking in digits. The digits for eleven are <say-as interpret-as="characters">11</say-as>.
Phrases can be substituted, like the <sub alias="United States of America">USA</sub>.
Finally, I can speak a paragraph with two sentences.
<p><s>Here is sentence one.</s><s>Here is sentence two.</s></p>
</speak>Step 3: Select your specifications
Then, you need to specify the preferred Gender, the targeted language, and the voice type.
After adding the required information, click Continue.
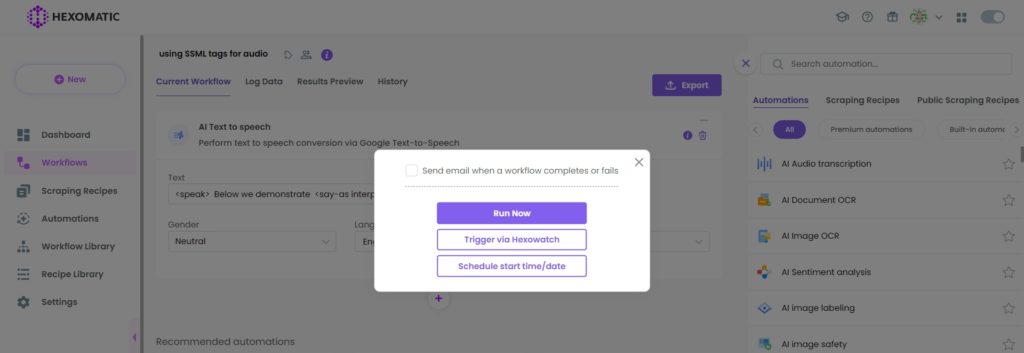
Step 4: Run your workflow
Now, you can run your workflow to get the audio file.
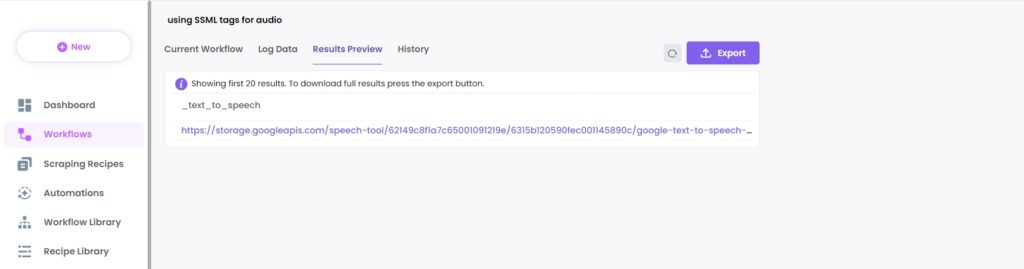
Step 5: View and Save the results
Once the workflow has finished running, you can view the results and export them to CSV or Google Sheets.
In this case, you will get a storage audio file. It will be exported to your device with just a click.
Automate & scale time-consuming tasks like never before
Marketing Specialist | Content Writer
Experienced in SaaS content writing, helps customers to automate time-consuming tasks and solve complex scraping cases with step-by-step tutorials and in depth-articles.
Follow me on Linkedin for more SaaS content