
E-commerce allures more and more people into this industry, making it an inseparable part of their lives. As online stores multiply and the number of consumers increases, there is a high demand for data collection, which can be used to make the right decisions, create competitive strategies, increase customer satisfaction, and more.
Considering this pivotal role of data extraction, businesses that want to succeed in the eCommerce niche should learn how to scrape the required data effectively.
In this article, we will show you how to scrape data from Amazon using Python and offer you an alternative that doesn’t require coding skills.
Simply follow the steps mentioned below and level up your eCommerce game with the right data collection techniques!
Some basic requirements
In order to scrape data from Amazon, you will need the following components:
Python– The vast collection of libraries makes Python one of the best programming languages for web scraping. If you don’t have one on your computer, make sure to install it.
Beautiful Soup– This is one of the best web scraping libraries for Python. It’s relatively easy to use. Once you install Python, you can also install Beautiful Soup by:
pip install bs4
General understanding of HTML tags– Learn the basics of HTML tags to help you scrape Amazon with Python.
Web browser– You can use a web browser like Google Chrome or Mozilla Firefox in order to toss out unnecessary information from a website by using specific IDs and tags for filtering.
Main steps on how to get data from Amazon using Python
Create a user-agent
Some websites use certain protocols for blocking any kind of bots that try to access their data. That’s why you need to create a User-agent in order to access the data of these websites.
Here is an example of a user-agent:
HEADERS = {‘User-Agent’:
‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36’,
‘Accept-Language’: ‘en-US, en;q=0.5’}
Send a request to a URL
Now, you will need to send a request to the webpage for accessing data:
URL = “https://www.amazon.com/Sony-PlayStation-Pro-1TB-Console-4/dp/B07K14XKZH/”
webpage = requests.get(URL, headers=HEADERS)
Create a soup of information
The ‘webpage’ variable holds the response obtained from the website. Supply the content of this response and specify the parser type when using the Beautiful Soup function.
soup = BeautifulSoup(webpage.content, “lxml”)
Lxml serves as a high-speed parser utilized by Beautiful Soup to dissect HTML pages into intricate Python objects. Typically, four types of Python Objects are extracted:
Tag: These correspond to HTML or XML tags, encompassing names and attributes.
NavigableString: This represents the text enclosed within a tag.
BeautifulSoup: In essence, it encapsulates the entire parsed document.
Comments: Lastly, these encompass any remaining segments of the HTML page not classified within the above three categories.
Extract the product title
By employing the find() function, which is designed for pinpointing specific tags with particular attributes, we are able to identify the Tag Object that contains the product’s title.
By employing the find() function, which is designed for pinpointing specific tags with particular attributes, we are able to identify the Tag Object that contains the product’s title.
# Outer Tag Object
title = soup.find(“span”, attrs={“id”:’productTitle’})
Next, we extract the NavigableString Object nested within:
# Inner NavigableString Object
title_value = title.string
Finally, we eliminate extra spaces and convert the object into a string value:
# Title as a string value
title_string = title_value.strip()
To understand the data types of each variable, we can use the type() function:
# Printing types of values for efficient understanding
print(type(title))
print(type(title_value))
print(type(title_string))
print()
This code yields the following output:
<class ‘bs4.element.Tag’>
<class ‘bs4.element.NavigableString’>
<class ‘str’>
Product Title = Sony PlayStation 4 Pro 1TB Console – Black (PS4 Pro)
Similarly, we can apply analogous procedures to obtain tag values for other product details such as “Price of the Product” and “Consumer Ratings.”
Extract product information
Now you can extract the product information with the following code:
from bs4 import BeautifulSoup
import requests
# Function to extract Product Title
def get_title(soup):
try:
# Outer Tag Object
title = soup.find(“span”, attrs={“id”:’productTitle’})
# Inner NavigableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip()
# # Printing types of values for efficient understanding
# print(type(title))
# print(type(title_value))
# print(type(title_string))
# print()
except AttributeError:
title_string = “”
return title_string
# Function to extract Product Price
def get_price(soup):
try:
price_span = soup.find(“span”, attrs={“class”:’a-price’})
price = price_span.find(“span”, attrs={“class”:’a-offscreen’}).text
except AttributeError:
price = “”
return price
# Function to extract Product Rating
def get_rating(soup):
try:
rating = soup.find(“i”, attrs={‘class’:’a-icon a-icon-star a-star-4-5′}).string.strip()
except AttributeError:
try:
rating = soup.find(“span”, attrs={‘class’:’a-icon-alt’}).string.strip()
except:
rating = “”
return rating
# Function to extract Number of User Reviews
def get_review_count(soup):
try:
review_count = soup.find(“span”, attrs={‘id’:’acrCustomerReviewText’}).string.strip()
except AttributeError:
review_count = “”
return review_count
# Function to extract Availability Status
def get_availability(soup):
try:
available = soup.find(“div”, attrs={‘id’:’availability’})
available = available.find(“span”).string.strip()
except AttributeError:
available = “”
return available
if __name__ == ‘__main__’:
# Headers for request
HEADERS = {‘User-Agent’:
‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36’,
‘Accept-Language’: ‘en-US, en;q=0.5’}
# The webpage URL
URL = “https://www.amazon.com/Sony-PlayStation-Pro-1TB-Console-4/dp/B07K14XKZH/”
# HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Soup Object containing all data
soup = BeautifulSoup(webpage.content, “lxml”)
# Function calls to display all necessary product information
print(“Product Title =”, get_title(soup))
print(“Product Price =”, get_price(soup))
print(“Product Rating =”, get_rating(soup))
print(“Number of Product Reviews =”, get_review_count(soup))
print(“Availability =”, get_availability(soup))
print()
Output:
Product Title = Sony PlayStation 4 Pro 1TB Console – Black (PS4 Pro)
Product Price = $473.99
Product Rating = 4.7 out of 5 stars
Number of Product Reviews = 1,311 ratings
Availability = In Stock.
Now that you’ve learned how to extract data from a single Amazon webpage, you can apply the same script to other web pages. All you have to do is change the URL.
Fetch links from the Amazon search results webpage
Instead of scraping a single Amazon webpage, you can also extract search results data, which is more beneficial for comparing prices, ratings, etc.
To extract the search results webpage, you will need the find all() function:
# Fetch links as List of Tag Objects
HEADERS = { ‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \ (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36’,
‘Accept-Language’: ‘en-US,en;q=0.9,ru;q=0.8,uk;q=0.7’ }
URL = ‘https://www.amazon.com/s?k=playstation+4&ref=nb_sb_noss_2’
search_page = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(search_page.content, “lxml”)
links = soup.find_all(“a”, attrs={‘class’:’a-link-normal s-no-outline’})
The find_all() function provides an iterable containing multiple Tag objects. Then, you iterate through each Tag object to extract the link stored as the value for the href attribute.
# Store the links
links_list = []
# Loop for extracting links from Tag Objects
for link in links:
links_list.append(link.get(‘href’))
We gather the links into a list, enabling us to iterate through each link and extract product details.
# Loop for extracting product details from each link
for link in links_list:
new_webpage = requests.get(“https://www.amazon.com” + link, headers=HEADERS)
new_soup = BeautifulSoup(new_webpage.content, “lxml”)
print(“Product Title =”, get_title(new_soup))
print(“Product Price =”, get_price(new_soup))
print(“Product Rating =”, get_rating(new_soup))
print(“Number of Product Reviews =”, get_review_count(new_soup))
print(“Availability =”, get_availability(new_soup))
We make use of the previously crafted functions for extracting product information. While this method of creating multiple soups may introduce some slowness into the code, it ensures a thorough price comparison across various models and deals.
Use Python to scrape Amazon webpages
Here is a complete working Python script for scraping several Amazon products:
import requests
from bs4 import BeautifulSoup
def get_price(soup):
try:
price_span = soup.find(“span”, attrs={“class”:’a-price’})
price = price_span.find(“span”, attrs={“class”:’a-offscreen’}).text
except AttributeError:
price = “”
return price
def get_rating(soup):
try:
rating = soup.find(“i”, attrs={‘class’:’a-icon a-icon-star a-star-4-5′}).string.strip()
except AttributeError:
try:
rating = soup.find(“span”, attrs={‘class’:’a-icon-alt’}).string.strip()
except:
rating = “”
return rating
def get_review_count(soup):
try:
review_count = soup.find(“span”, attrs={‘id’:’acrCustomerReviewText’}).string.strip()
except AttributeError:
review_count = “”
return review_count
def get_availability(soup):
try:
available = soup.find(“div”, attrs={‘id’:’availability’})
available = available.find(“span”).string.strip()
except AttributeError:
available = “”
return available
def extract_product_details(url):
HEADERS = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \ (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36’,
‘Accept-Language’: ‘en-US,en;q=0.9,ru;q=0.8,uk;q=0.7’ }
response = requests.get(url, headers=HEADERS)
soup = BeautifulSoup(response.content, “lxml”)
title = soup.find(“span”, attrs={“id”:’productTitle’}).string.strip() if soup.find(“span”, attrs={“id”:’productTitle’}) else “”
price = get_price(soup)
rating = get_rating(soup)
review_count = get_review_count(soup)
availability = get_availability(soup)
product = {
‘title’: title,
‘price’: price,
‘rating’: rating,
‘review_count’: review_count,
‘availability’: availability
}
return product
if __name__ == ‘__main__’:
deal_urls = [
‘URL_OF_DEAL_1’,
‘URL_OF_DEAL_2’,
‘URL_OF_DEAL_3’,
# Add more URLs as needed
]
# Iterate through the URLs and extract product details
for url in deal_urls:
product_details = extract_product_details(url)
print(“Product Details for Deal:”, url)
for key, value in product_details.items():
print(key + “:”, value)
print(“\n”)
Replace ‘URL_OF_DEAL_1’, ‘URL_OF_DEAL_2’, and ‘URL_OF_DEAL_3’ with the actual URLs of the Amazon product deals you want to scrape. You can expand the deal_urls list with more URLs as needed.
This script defines a function extract_product_details to extract product information and then iterates through the list of URLs to scrape and print the details for each deal.
How to capture Amazon data without any coding skills
Amazon web scraping with Python is great, but what if you don’t have any coding skills?
Well, here’s great news for you!
Now you can scrape Amazon data in seconds without using any programming language. One of the tools that can help you scrape Amazon product data is Hexomatic.
All you have to do is choose the automation that fits your needs and follow the simple steps to extract data in no time.
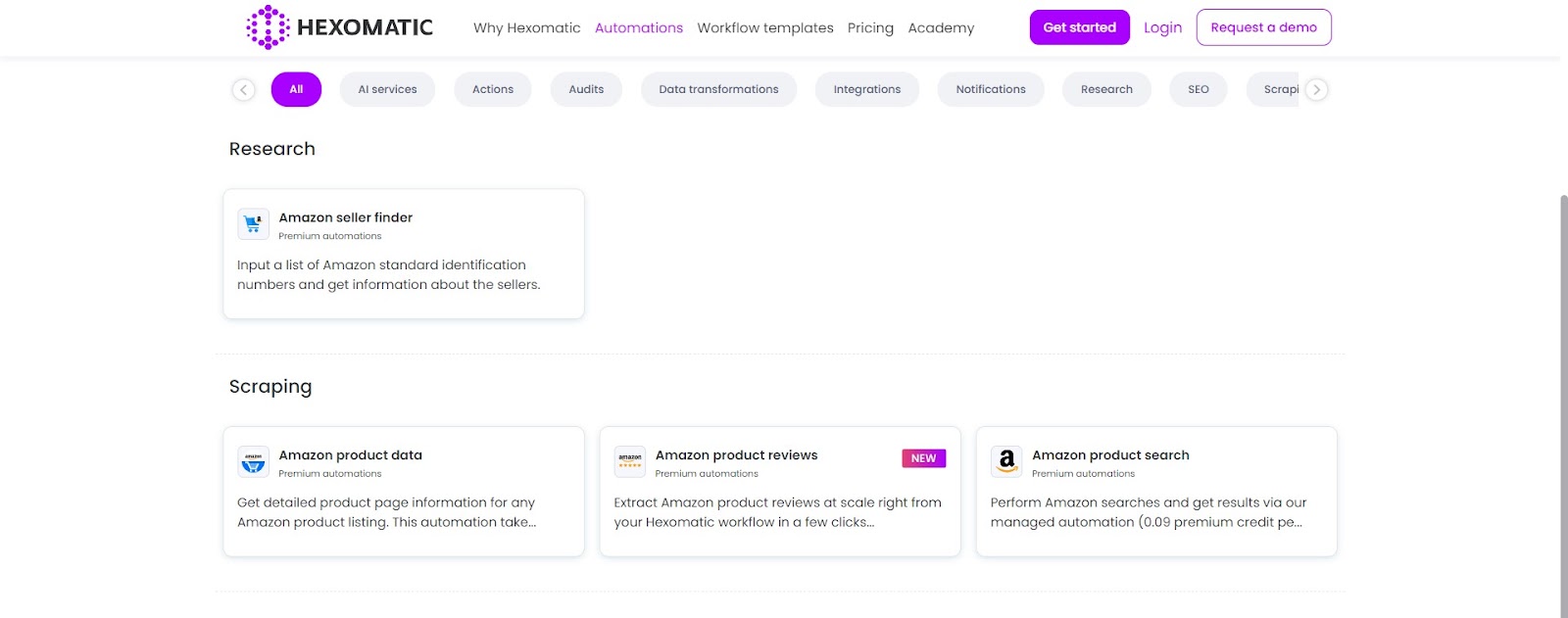
Currently, Hexomatic has the following Amazon-related automations:
- – Amazon product search– Perform Amazon searches and get results via our managed automation.
- – Amazon seller finder– Input a list of Amazon standard identification numbers and get information about the sellers.
- – Amazon product data– Get detailed product page information for any Amazon product listing. This automation takes an ASIN number and returns product page data including title, description, price, and reviews.
- – Amazon product reviews– Extract Amazon product reviews at scale right from your Hexomatic workflow in a few clicks. Insert the ASIN of the desired product, and Hexomatic will return a list of product reviews, including the rating of the product, full review texts, and more.
Scraping Amazon data with Hexomatic
It’s super easy to scrape Amazon data with Hexomatic. First, you should log into Hexomatic and head over to the Automations page.

Then, search for Amazon, and all the Amazon-related automations will appear on your screen.
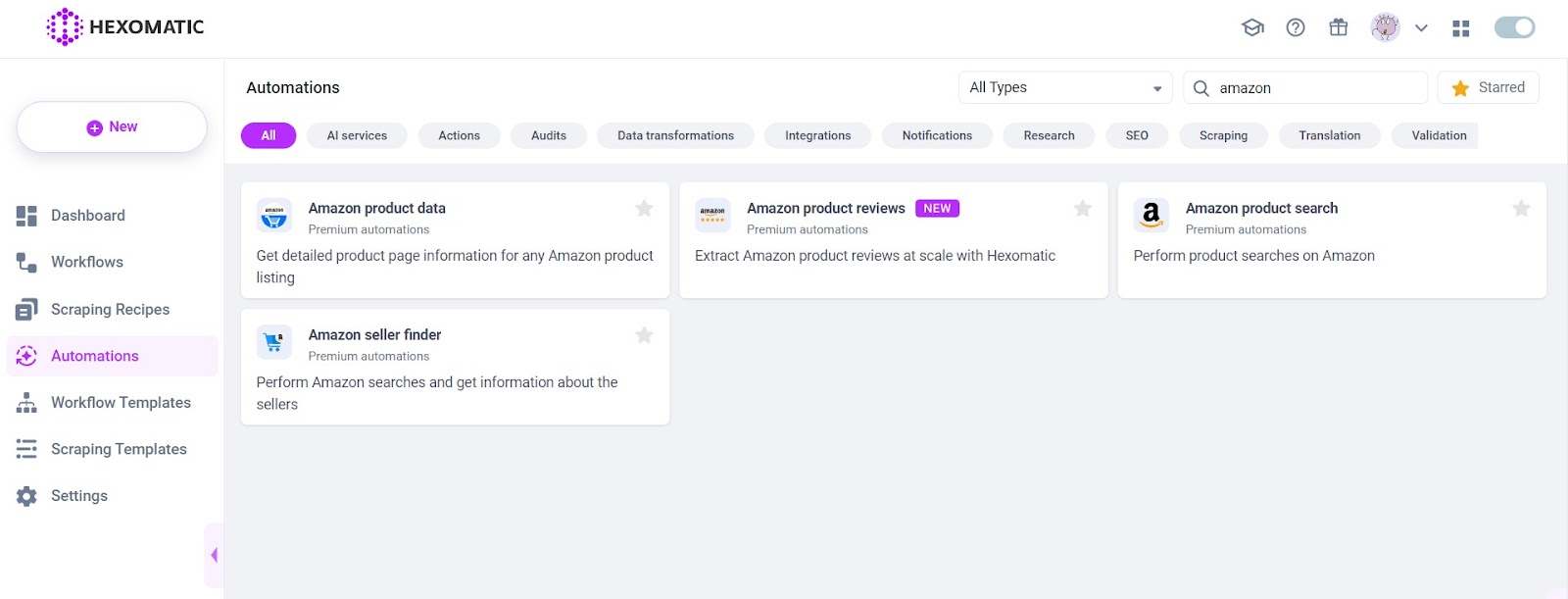
After, choose the one you want and click on the button Create Workflow. For this article, we have used the Amazon product search automation.
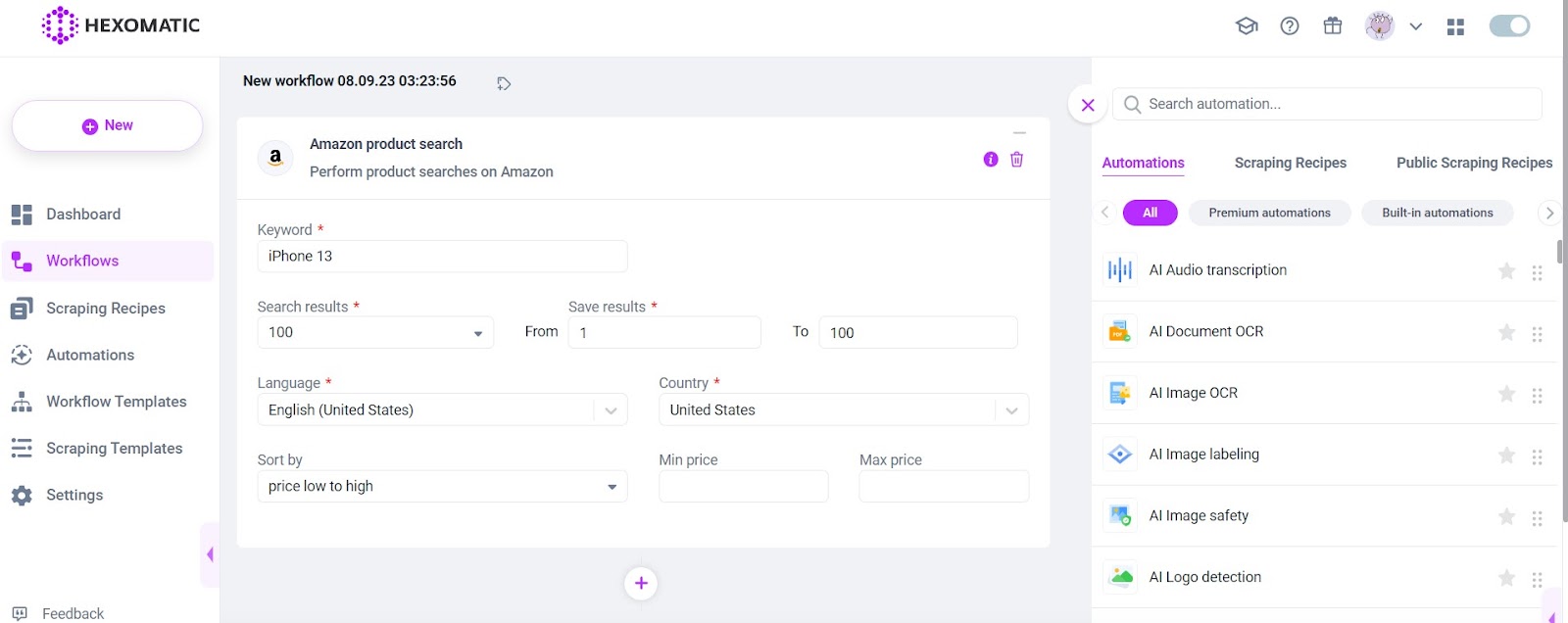
Write down the keyword, choose the language, and location, and run the workflow to capture the required data.
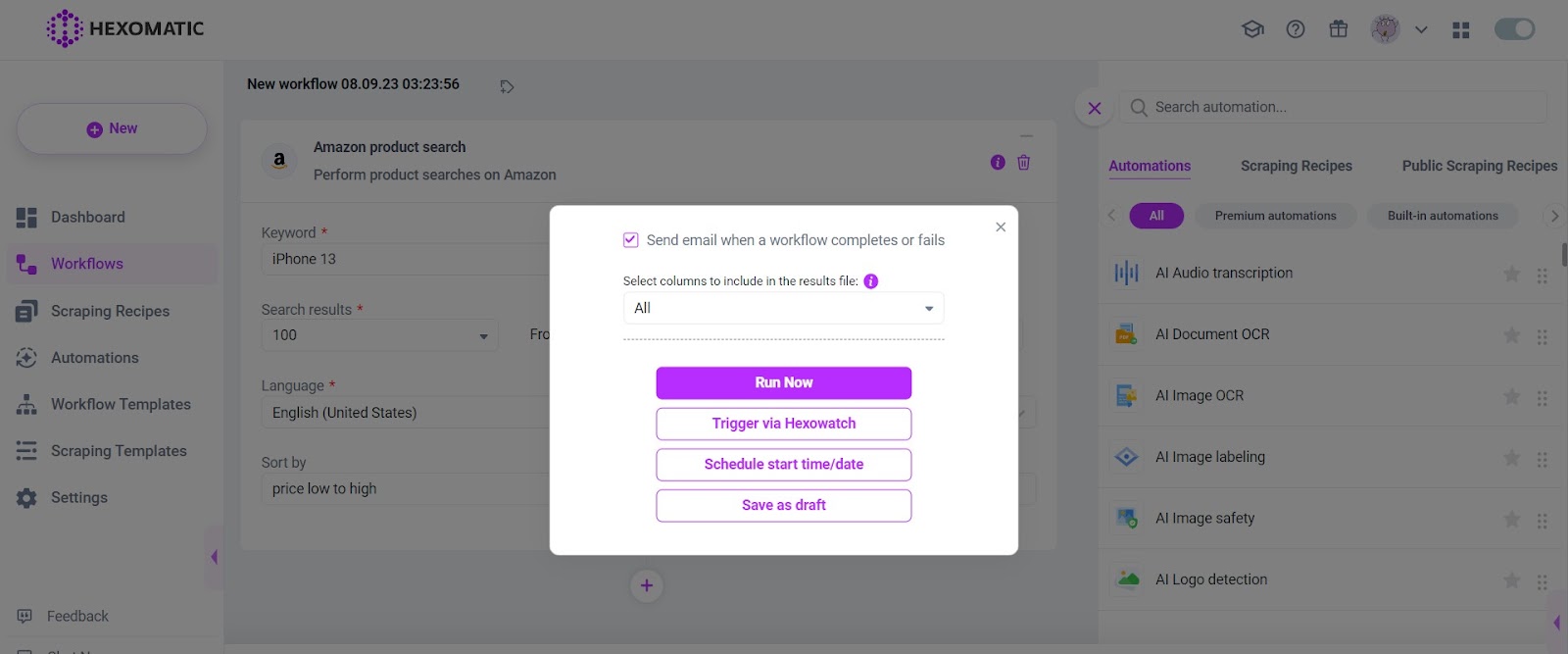
Voila! Now you can save the scraped Amazon data into a Google Spreadsheet for your convenience.
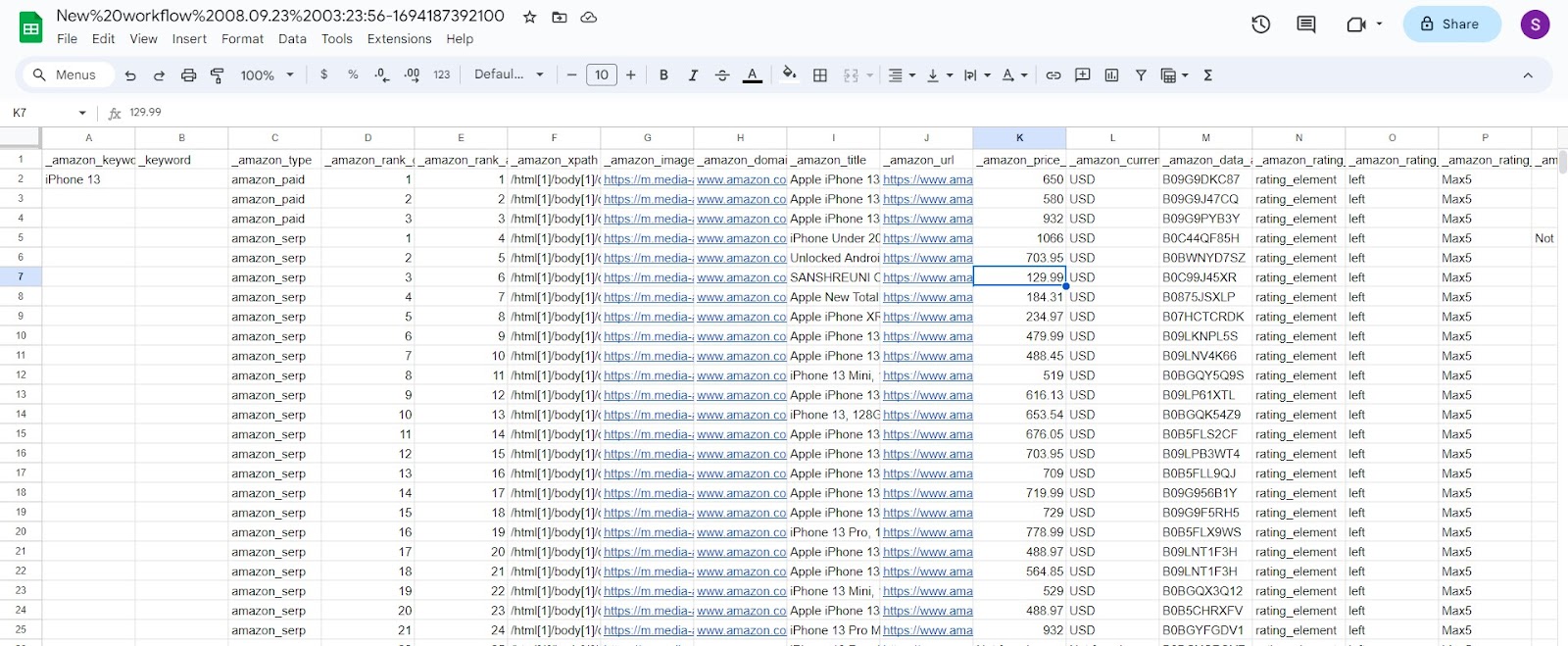
Now you know how to scrape data from Amazon using Python and Hexomatic. It’s up to you to choose the one that best fits your needs. Python is great if you’re tech-savvy and can write code.
But if you’re looking for a faster and easier solution, it’s better to choose the automations provided by Hexomatic. The latter will allow you to scrape the required data in a few seconds.
Automate & scale time-consuming tasks like never before

Content Writer | Marketing Specialist
Experienced in writing SaaS and marketing content, helps customers to easily perform web scrapings, automate time-consuming tasks and be informed about latest tech trends with step-by-step tutorials and insider articles.
Follow me on Linkedin