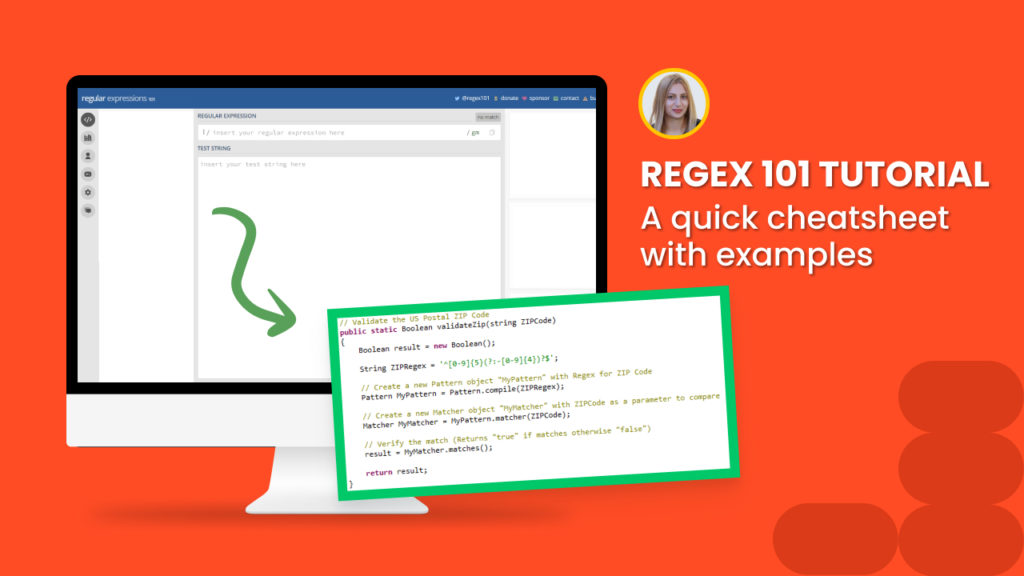
A Regular expression (in short- regex) is a text string that enables creating patterns for matching, locating, and managing text. They are commonly used for search and replace operations and are super powerful for solving any parsing issues.
You may wonder how regex can be used in web scraping and what advantages it can bring.
Well. In web scraping, regex is ideal for getting only the relevant information from a huge amount of data. It’s especially useful for websites that do not have a clear structure to pull out key elements. Additionally, regex can be used for validating any character combinations (for example, special characters).
Hexomatic allows you to use regular expressions to scrape data:
#1 Using our Regex automation.
#2 Applying regular expressions in our scraping recipe builder.
The tutorial reveals the Regex cheatsheet and explains how to use our regex automation versus applying regex in the scraping recipe builder and when to use each.
#1 How to use regex automation to scrape data
This section demonstrates how to use our regex automation.
First and foremost, this automation can be used when it is necessary to exclude unnecessary text and scrape only the relevant content.
For example, you want to scrape only full names from the list but while using the scraping recipe, other data is selected automatically.
This can’t be excluded via the scraping recipe builder. Here is where our Regex automation comes in handy.
Example A
Step 1: Create a blank scraping recipe
To get started, go to your dashboard and create a blank scraping recipe.
Step 2: Add the web page URL
Next, add the web page URL to scrape data.
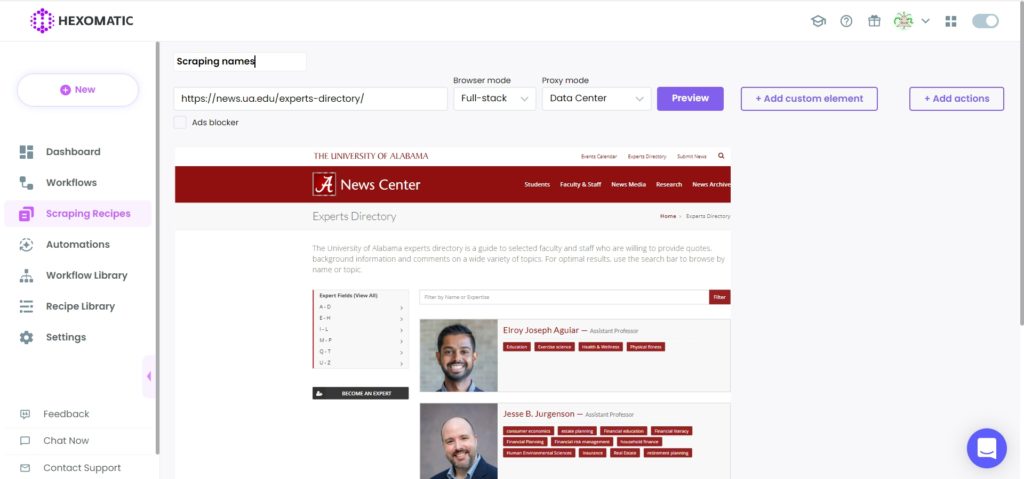
Step 3: Select elements to scrape
Here, we are going to scrape full names of experts by choosing Select All option.
The problem here is that while selecting full names, the academic titles are being selected automatically and scraping recipe builder doesn’t allow to exclude these.
That’s why we need to scrape full names with academic titles, then run our Regex automation to get the desired results.
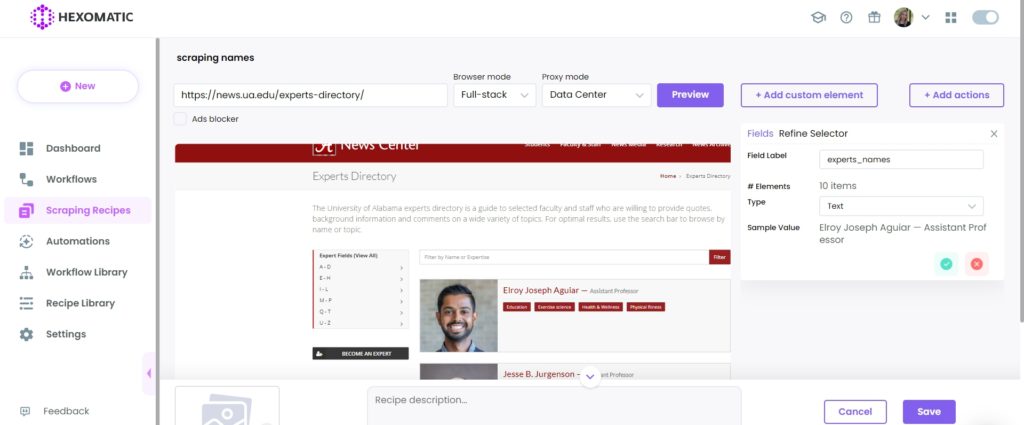
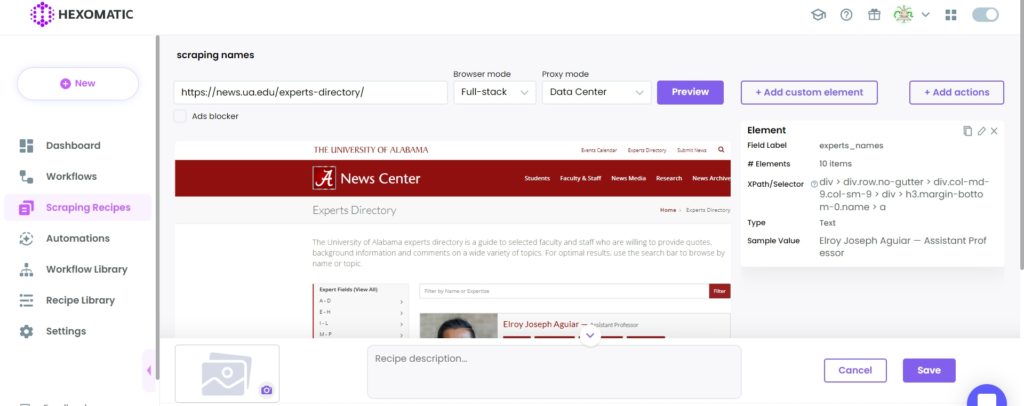
After selecting, Save the recipe.
Step 4: Use the recipe in a workflow
To run the Regex automation on the scraped data, you need to use the previously created recipe in a workflow.
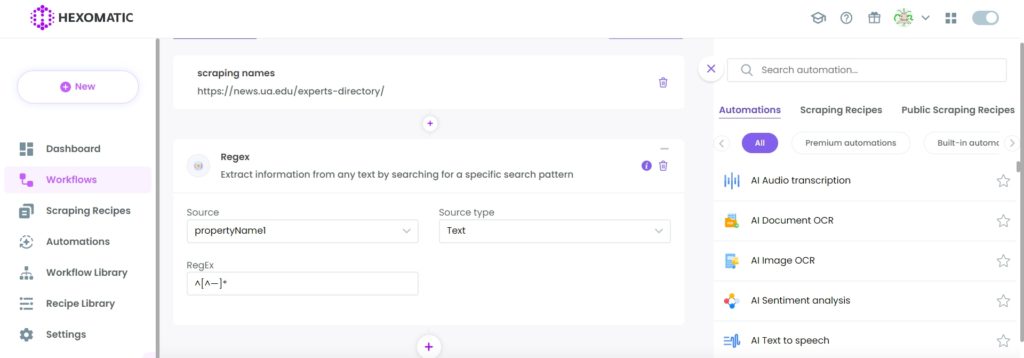
Step 5: Add the Regex automation
Next, you need to add the Regex automation, select “experts_names” as the source, “Text” as the source type.
Then, add the ^[^—]* regex.
Step 6: Run the workflow
Finally, you can run your workflow.
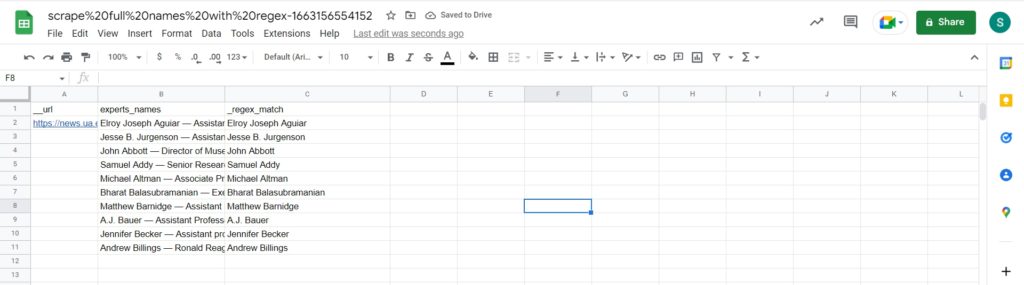
Step 7: View the results
Once the workflow has finished running, you can view the results and export them to CSV or Google Sheets.
Example B
Now let’s see another example of using our Regex automation.
Often, the element you want to scrape is not displayed on the page directly, but it exists in the HTML code. Good news is that Hexomatic can solve this problem in a few clicks.
In this case, it is necessary to use the combination of our HTML grabber automation+ Regex automation.
In this example, we are going to get a publication date from the HTML code of a specific web page. Here, regular expression helps to save time and effort in the search for a specific element to scrape and the HTML grabber helps to get the HTML code of the page.
Here we go.
Step 1: Create a new workflow
Go to your dashboard and create a new workflow by choosing the blank option.
Step 2: Add the web page URL
Next, choose the Data automation as a starting point and add the web page URL using the Manual paste/ list of inputs option.
Step 3: Add the HTML grabber automation
In order to get the HTML code of the targeted page, you need to first run the HTML grabber automation.
So, add it from the automations list and select “data input” as the source.
Step 4: Add the Regex automation
Next, add the Regex automation, selecting “page source code url” as the source, “URL” as the source type. And, finally, paste the appropriate regex in the “RegEx” field. In this case, the regex is “datePublished”:([\s\S]*?)”,
Then, click continue.
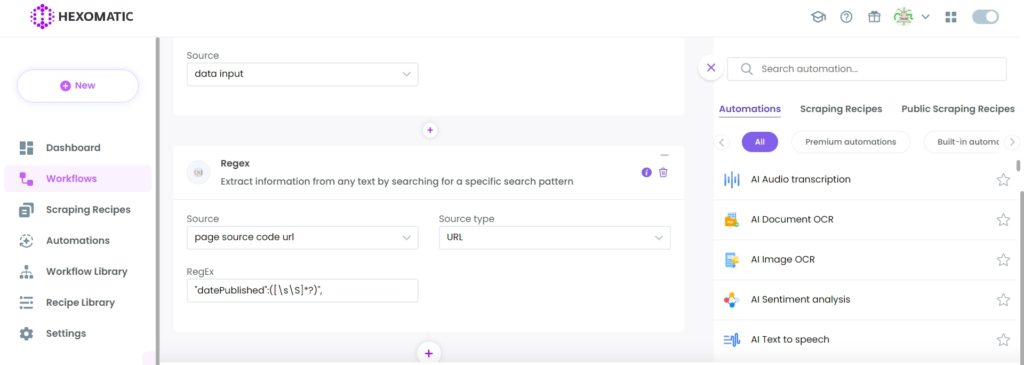
Step 5: Run or schedule the workflow
Now, you can run your workflow or schedule it.
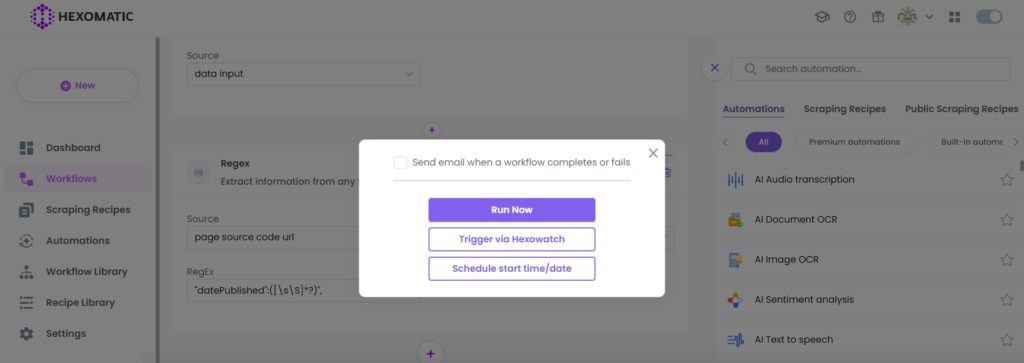
Step 6: View and save the results
Once your workflow has finished running, you can view the results and export them to CSV or Google Sheets.
In this case, our inputted regex returned the book publication date as was expected.
#2 How to use regex to scrape data using only our scraping recipe builder
Hexomatic allows using regular expressions to make it easier to scrape data using our scraping recipe builder.
Our scraping recipe builder allows using regex for getting the relevant elements from a list of elements, excluding non-relevant ones.
Example
For example, there are 10 headlines on the page, but you want to scrape only specific headlines automatically.
To learn how to do that, refer to this example:
Step 1: Create a new scraping recipe
Create a blank scraping recipe from your dashboard.
Step 2: Add the web page URL
Add the web page URL you want to scrape. Then, click Preview.
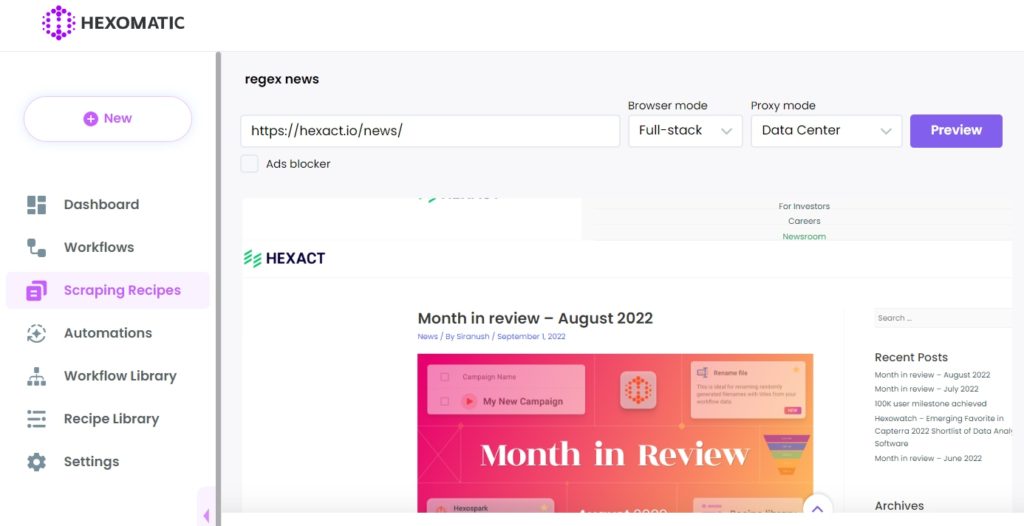
Step 3: Select elements to scrape
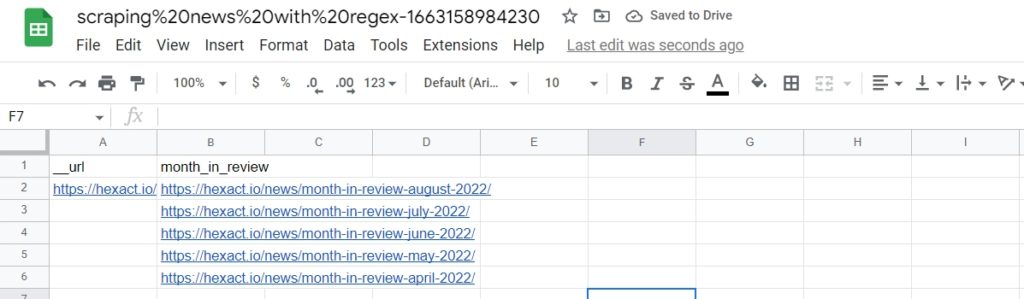
Now, select the elements to scrape choosing the Select All option to get all the article links on the page. So, we will have 10 headlines, but need to scrape only “Month in Review” article links.
So, how to act in this situation?
Follow the steps below to get things done.
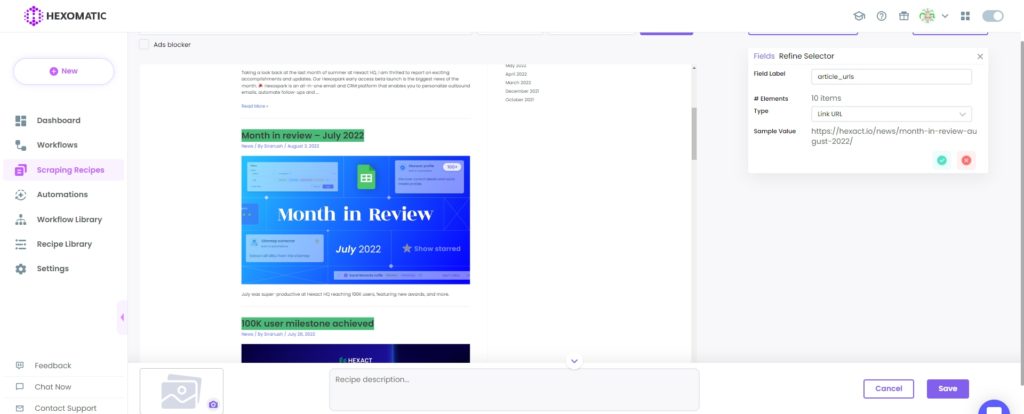
Step 4: Add the regex using the refine selector
Go to the refine selector section and add the ^.*month-in-review.*$ regex in the “Pattern” field.
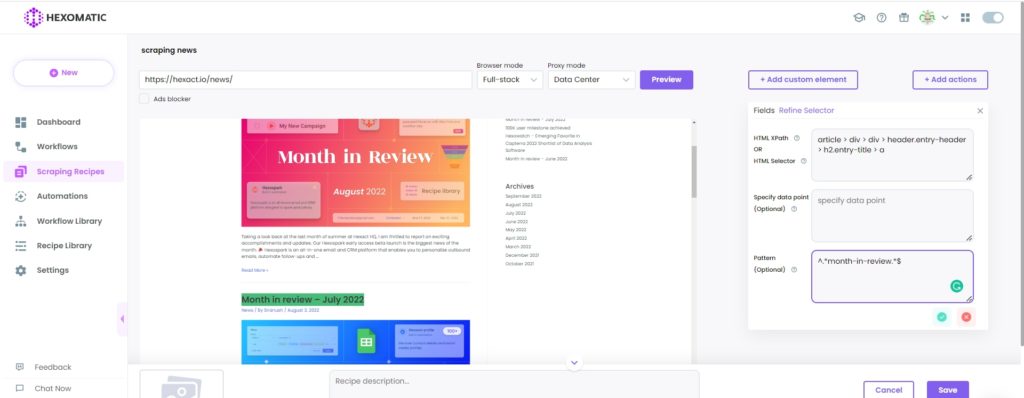
After saving the pattern, you will get only the relevant article URLs.
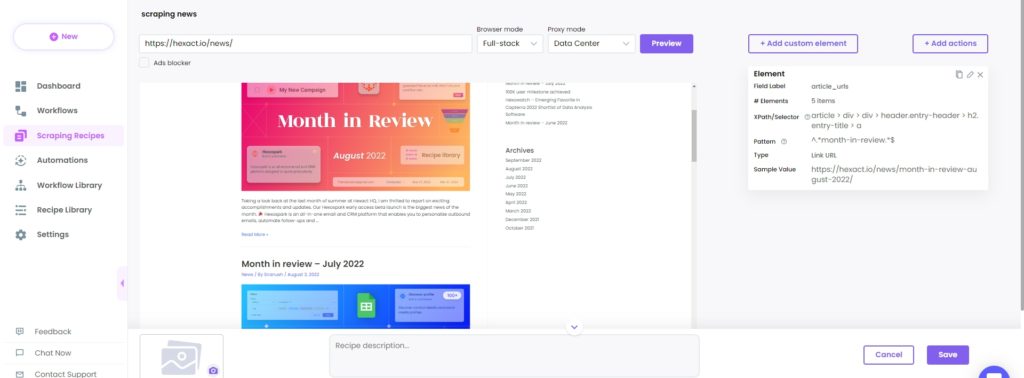
Step 5: Run the recipe in a workflow
In order to view and save the scraped data, it is necessary to use the recipe in a workflow.
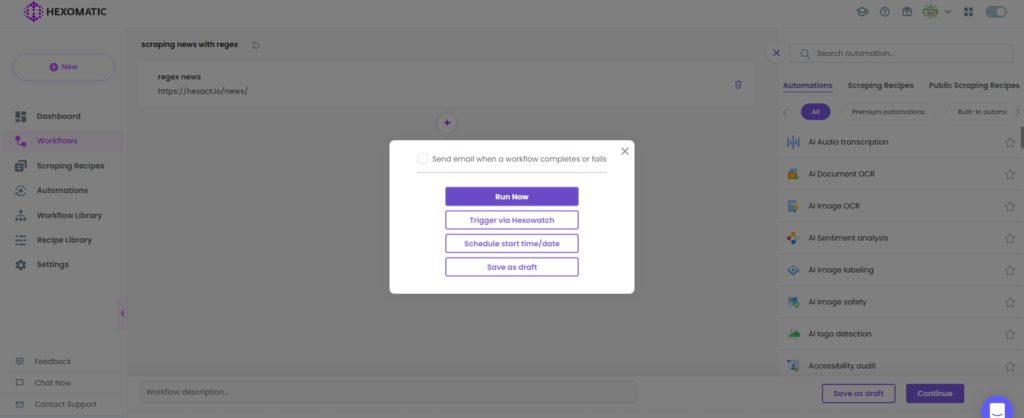
Step 6: Run the workflow
Run the workflow.
Step 7: View and Save the results
Once the workflow has finished running, you can view the results and export them to CSV and Google Sheets.
Automate & scale time-consuming tasks like never before
Marketing Specialist | Content Writer
Experienced in SaaS content writing, helps customers to automate time-consuming tasks and solve complex scraping cases with step-by-step tutorials and in depth-articles.
Follow me on Linkedin for more SaaS content