
Ever wondered how people collect loads of data from the internet? Well, they use web scraping tools or services to do it way faster than manual methods.
Since many tasks rely on analyzing data, web scraping has become essential in industries like marketing, eCommerce, real estate, and medicine.
Let’s explore what web scraping is and how it can save you time by automating data collection instead of tediously copying and pasting from websites!
What is web scraping?
Web scraping is a technique used to extract data from websites. It involves automated software accessing and gathering information from web pages in large quantities. This data can then be analyzed, stored, or used for various purposes such as market research, competitor analysis, price monitoring, and more.
Web scraping is usually done with the help of web scrapers. The latter mimic human browsing behavior to access web pages, retrieve specific information, and store it for further analysis or use. Web scrapers can target various types of data, including text, images, links, and structured content such as tables or lists.
There are different types of web scrapers, ranging from simple scripts written in programming languages like Python or JavaScript to more advanced tools with graphical user interfaces (GUIs) that allow users to configure scraping tasks without writing code. Some web scrapers are specifically tailored for scraping particular types of websites, such as e-commerce sites, social media platforms, or news websites, while others offer more general-purpose scraping capabilities.
How do web scrapers work?
Now that we know what web scraping is, let’s find out how exactly web scrapers work:

- Sending HTTP requests
The web scrapers start the process by sending HTTP requests to the target website’s server. These requests specify the webpage URL from which data needs to be extracted.
- Receiving web page content
After receiving the HTTP request, the target website’s server responds by sending back the requested web page’s content. This content typically consists of HTML code, which contains the structure and elements of the webpage.
- Parsing HTML
The web scraper parses the HTML content of the webpage to identify and locate the data elements that need to be extracted. It analyzes the HTML structure, tags, attributes, and CSS selectors to pinpoint the specific data points of interest.
- Extracting data
Once the relevant data elements are identified, the web scraper extracts the desired information from the HTML content. This may include text, images, links, tables, or other types of content present on the webpage.
In some cases, web pages may contain dynamic content that is loaded dynamically via JavaScript or AJAX requests. Web scrapers may use techniques such as headless browsing or dynamic rendering to interact with and retrieve dynamically generated content.
- Navigating multiple pages
For scraping multiple pages or sections of a website, the web scraper may implement logic to navigate through paginated results, follow links to other pages, or interact with site navigation elements.
- Data processing and storage
After extracting the desired data, the web scraper may perform additional processing, such as cleaning, filtering, or formatting the data. The scraped data is then typically stored in a structured format, such as a database, spreadsheet, or file.
What type of web scrapers are there?
There are several types of web scrapers, each with its own characteristics and functionalities. Here are some common types of web scrapers:
1. Browser extensions
Browser extensions are tools that extend the functionality of web browsers. They are typically installed directly into the browser and can be accessed via the browser’s toolbar or menu.
Browser extension web scrapers offer various functionalities for extracting data from web pages. This may include selecting specific elements to scrape using point-and-click interfaces, defining scraping rules, and saving scraped data in various formats.
With a browser extension, you can easily install the extension and select how you want to scrape data from any website of your choice. The scraped data can be downloaded in CSV or any other downloadable format, making it convenient for further analysis or storage.
While browser extensions offer ease of use and convenience, they do have limitations. One significant limitation is that they can only scrape one page at a time. Therefore, if you need to scrape a large amount of data or multiple pages, there may be better solutions than a browser extension for your needs.
2. Installable software
Installable software for web scraping is becoming popular as the demand for data continues to grow. Many companies offer a wide range of installable software solutions tailored to various scraping needs.
To get started with installable software, you’ll need to download and install it on your PC. Fortunately, most web scraping software is designed to be compatible with Windows-based systems, so it can easily be integrated with your existing setup.
Once installed, configuring the software is a simple process. Simply set up your scraping parameters and preferences, and you’re ready to start scraping the data you need.
One of the key advantages of installable software is its flexibility in scraping data. Unlike browser extensions, which are limited to scraping one page at a time, installable software allows you to scrape multiple pages simultaneously. This makes it ideal for scraping small to medium chunks of data from various sources.
As with browser extensions, the scraped data from installable software is typically available in CSV or other downloadable formats, making it easy to store, analyze, and share as needed.
3. Cloud based
Cloud-based web scraping is widely considered the most robust solution compared to other tools available in the market. With its operation and advanced capabilities, it offers unmatched reliability and efficiency for data extraction tasks.
One of the most significant advantages of cloud-based web scraping is the elimination of software installation on your PC. You can access the platform directly from your web browser, without the need for complex setup processes or compatibility issues. Simply configure your scraping plan and requirements, and you’re ready to go!
Unlike browser extensions that may have limitations on the amount of data you can scrape, cloud-based web scraping offers scalability. There’s no upper limit on the amount of data you can extract, thanks to its ability to run on multiple computing environments. Whether you need to scrape a few web pages or thousands of them, the cloud-based service can handle it easily in a short period.
| Feature | Types of Web Scrapers | ||
| 1. Browser Extension | 2. Installable Software | 3. Cloud-Based Web Scraper | |
| Installation | Installed directly in a browser | Downloaded and installed on PC | Accessed via a web browser |
| Compatibility | Browser-specific | Windows-based | Platform-independent |
| Data Format | CSV or downloadable format | CSV or downloadable format | API and downloadable format |
| Scraping Capability | Single page scraping | Multiple page scraping | Scalable for large-scale scraping |
| Ease of Use | User-friendly interface | Configuration required | Configuration required |
| Hassle-Free Operation | Limited manual intervention | Requires manual intervention for start-stop | Automated operation |
| Scalability | Limited scalability for large data volumes | Limited scalability for large data volumes | Scalable for large data volumes |
| Reliability | Limited reliability for complex scraping tasks | Reliable for small to medium chunks of data | Highly reliable for large-scale scraping |
| Best Solution For | Small data extraction tasks | Small to medium data extraction tasks | Large-scale scraping projects |
What are web scrapers used for?
Web scrapers have so many applications! Let’s explore some common ones now:
– Real estate listing scraping
Many real estate agencies use web scraping to compile databases of available properties for sale or rent. By scraping MLS listings, agencies can create APIs that populate their websites with up-to-date property information, enabling them to act as agents for these properties.
– Industry statistics and insights
Companies use web scraping to gather vast amounts of data, extracting industry-specific insights. These insights are then packaged and sold to companies operating within the respective industries. For instance, analyzing data on oil prices, exports, and imports enables companies to offer valuable insights to global oil companies.
– Comparison shopping sites
Websites and apps that have price comparisons between retailers often rely on web scraping. By scraping product data and pricing from multiple retailers regularly, these platforms provide users with valuable comparison data, aiding informed purchasing decisions.
– Lead generation
Web scraping is widely used for lead generation, particularly in the business-to-business space. Companies extract contact information from publicly available sources online, such as business directories and social media profiles, to identify potential customers or clients.
– Job market insights
HR professionals and recruiters utilize web scrapers to collect job postings, salary data, and skill requirements from job boards and career websites. This data provides valuable insights into job market trends, demand for specific skills, and salary benchmarks, aiding recruitment strategies and talent acquisition efforts.
– Competitor analysis
By monitoring competitors’ pricing strategies, product offerings, and customer reviews, companies can adapt their strategies to stay competitive in the market.
Check out our tutorials and webinar videos on how you can use web scraping for your business:
- How to scrape e-commerce product and price data – Webinar Video
- How to extract restaurant menus from photos using AI
- How to scrape the web with ChatGPT
- How to find and research recently funded companies with Google News and ChatGPT
- How to scrape Google Careers Jobs
- How to scrape videos from any website
- How to scrape phone numbers from websites
- How to scrape Amazon product data & track prices
- How to find contact details for any website, business, blogger, or journalist
What is the best web scraping tool for your needs?
While numerous web scraping tools are available online, the most efficient and time-saving ones are often cloud-based. Among these, Hexomatic can be a great solution! It doesn’t only scrape the required web pages in minutes but also automates tasks, allowing you to focus on what matters most- your business growth!
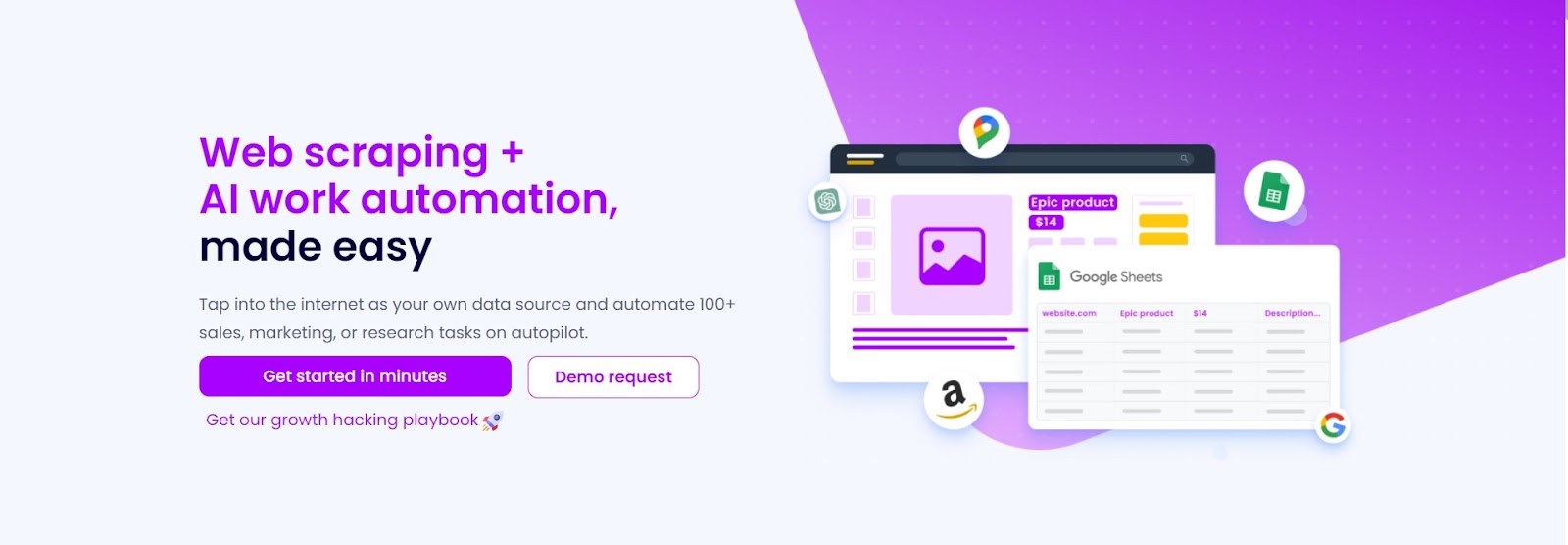
- – Efficiency: Hexomatic offers over 100 automations, saving you time and effort.
- – Comprehensive: It allows you to scrape web pages and automate tasks based on the gathered data.
- – Versatility: Hexomatic can be used as your personal assistant that can complete tasks, such as analyzing competitor data, writing product descriptions, creating marketing materials, and much more.
- – Integration: With ChatGPT integration, you can generate content and insights with ease.
- – Ease of use: Its user-friendly interface makes it accessible to all levels of users.
Automate & scale time-consuming tasks like never before

Content Writer | Marketing Specialist
Experienced in writing SaaS and marketing content, helps customers to easily perform web scrapings, automate time-consuming tasks and be informed about latest tech trends with step-by-step tutorials and insider articles.
Follow me on Linkedin